GAMES104-NOTE1
1.游戏引擎导论
- 什么是游戏引擎
- 底层框架
- 生产力工具
- 复杂性的系统艺术集合
- 核心难点:
- 游戏引擎最重要的难点是Realtime,必须在33毫秒之内将结果计算出来,是所有系统的计算结果计算出来,这就是现代游戏引擎设计的核心难点。
- 游戏引擎不仅仅是一系列的算法,更是生产力的工具,需要成熟的工具链
- 学习的方式:
以framework为基准,自上往下再细致学习研究
2. 分层
- Tool Layer 工具层
- Function Layer 基本功能层
- Resource Layer 资源层,包括数据等
- Core Layer 核心层,内存管理,容器分配,数学运算模块,脚本运行时环境
- Platform Layer 平台层,操作系统,平台文件系统,Graphics API, Platform SDK
2.1 Resource Layer:
以特定引擎的格式统一化导入
从Resource到Asset,通过Importer转换到引擎下
通过一个reference文件数据记录关联
GUID 做为唯一识别号
- Runtime 资源管理器, 虚拟的文件系统加载和卸载Asset
- 管理所有资源的生命周期
2.2 Function Layer:
Tick 模拟,利用现代计算机的性能,在一帧时间做一定事件
Logic(Camera,Motor,Controller,Animation,Physics) -> Render (Render Camera, culling, rendering, postprocess, present)
这一层经常与具体的游戏混合在一起
2.3 Core Layer:
数学库
SIMD: 指令池,整合多个运算到一个
内存管理:
表现优化:
- 内存池
- 减少cache miss
- 内存对齐
核心:
- Put data together 数据堆放在一起
- Access Data in order 按顺序访问
- Allocate and de-allocate as a block 一次一批的申请和释放
做一套引擎的数据结构,把内存管理起来
关于CPU,不仅仅看其主频,缓存大小也决定了跑分,同时缓存硬件成本也更高
什么是图灵机?
图灵机是一个虚拟的机器,由数学家阿兰·图灵1936年提出来的,尽管这个机器很简单,但它可以模拟计算机的任何算法,无论这个算法有多复杂。
现代电子计算机的计算模型其实就是这样一种通用图灵机,它能接受一段描述其他图灵机的程序,并运行程序实现该程序所描述的算法。
2.4 Platform Layer
对于不同的API,不同的操作系统的适配性问题
2.5 Tool Layer
以开发效率优先,而不是以性能优先。 这一层代码量往往比引擎代码还要多,可以选择Python,wpf等各种语言实现。
Digital Content Creation: 引擎与各个工具软件之间的数据互通转换- Asset Conditioning Pipeline
总结:
分层的核心思想:
- 越往上越灵活,越往下越稳定。
- 一定是上往下调用,不能反向
C++ 17使用了原EA寒霜引擎的定制的STL高效
一个引擎首先是从【CORE层】、【功能层】开始搭建
3. 如何构建游戏世界
3.1 游戏对象-GO
分类:
- 动态物
- 静态物
- 环境(天空,植被,地形系统)
- 其他的对象(空气墙)
3.2 组件化GO
组件化游戏对象,将各个部件做为一个组件自由拼装
弊端:需要频繁地访问组件时的效率问题
3.3 LOOP
TICK能力,现在引擎逐渐转到各个系统的tick
3.4 通信
- 互相通信的能力,替代最原始的HARD-CODE方式,使用事件的方式
3.5 场景管理器
Scene management
管理着场景内的GO
- 空间上的数据管理是场景管理的核心
- 一般引擎需要支持两到三种空间的划分法
3.6 时序性
期望游戏中的确定性,利用一个中间层去控制管理。 或者如GO Binding之间的顺序性
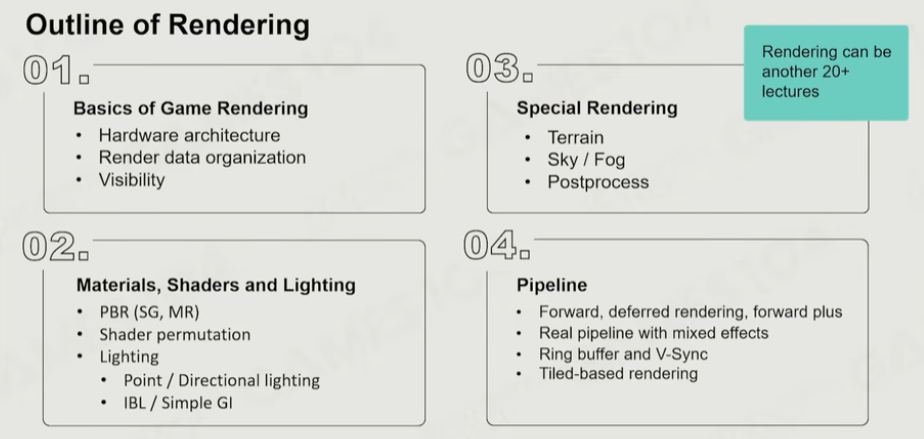
4.游戏引擎中的渲染实践
帧率的参考: >30帧, 实时。 10帧,可交互。 <10 offline rendering
挑战:
- 同时处理的物体对象和类型,实现的效果的复杂性
- 需要对于现在计算机硬件有一定的认知
- 更高的帧率要求,更高的显示分辨率
- 硬件环境对于游戏开发的限制
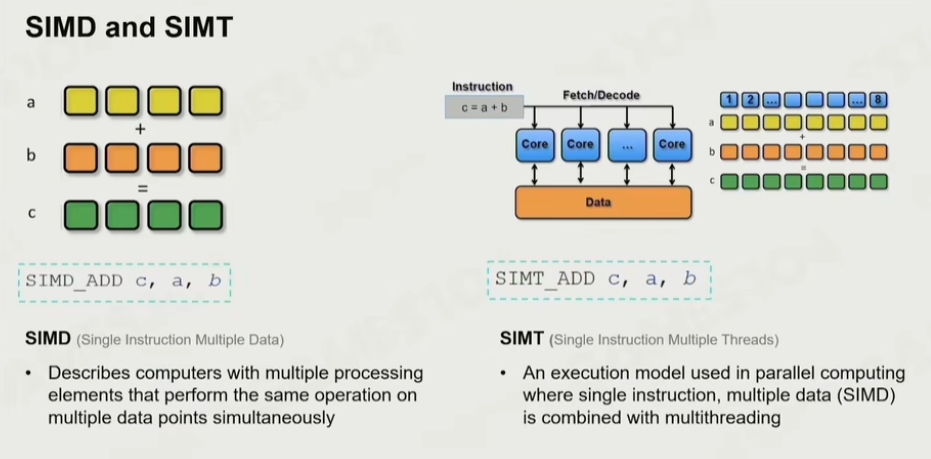
4.1 SIMD与SIMT
SIMD Single Instruction Multiple Data 单指令同时在多个数据点时执行相同运算
SIMT 更多的拥有SIMD的核,进行并行计算
C++ sse扩展宏
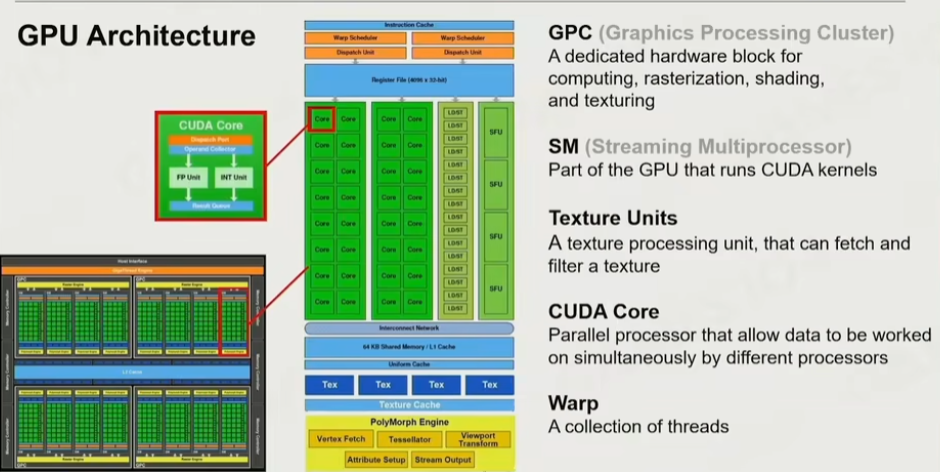
4.2 GPU架构
冯-诺依曼架构,把计算和数据分开,但这里的问题是找数据的过程会有性能的问题
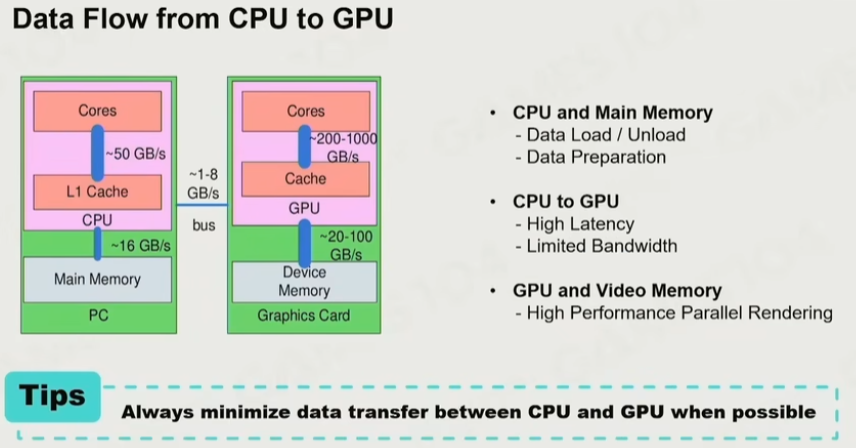
- 尽可能单向传输,从CPU转到GPU,而不要从GPU中读数据
- 缓存效率问题,提高达到更多的cache hit
4.3 GPU限制
- 内存的限制
- ALU的限制(数据计算)
- TMU的限制Texture Mapping Unit
- BW的限制Bandwidth
问题:为什么每个顶点都需要一个法线数据呢?
如果以面为顶点找法线,大部分情况是对的,但对于面是折面(如Cube)时,同样的顶点的法线可能完全不同
4.4 Submesh的概念
对于一个大的Mesh数据,通过取其中的数据,组合成各个小的submesh
- 但对于大量的submesh,可能会出现重复而导致内存浪费,这时需要使用一个Resource Pool 对于其进行管理。
4.5 GPU Batch Rendering
尽可能把绘制运算交给GPU,将相同的物体绘制一次批次传递给GPU,以加速渲染
4.6 PVS(Potential Visibility Set)
PVS的思想是基于多个Portal的结果,在某个位置上计算出最多能看到的地方结果,因此只需要渲染此范围内的物体
优势:
- BSP/Octree
- 更加的灵活
- 预加载资源基于PVS
4.7 GPU Culling
将BVH数据完全丢给GPU,返回Occlusion的数据。
Early-Z技术,先由GPU提前画一次深度图,在正式渲染时把看不到物体直接不渲染
4.8 纹理压缩
Block Compression:
分块后,取最亮最暗值,以及像素权重(可由距离决定),来存储数据
PC: DXTC算法
Mobile: ASTC,不再是严格4x4分块
4.9 Cluster-Based Mesh pipeline
由一个单独的GPU算法过程把mesh生成为众多的小mesh,通过分成很多很多mesh,交由GPU处理

5.渲染中的光和材质
5.1 理论基础
渲染方程

挑战:
-
- visiblity to light的问题,一块区域是否有光的问题? 最熟悉的解释方式就是shadow, irradiance的计算问题
radiance 辐射度, 黑体辐射的逻辑,一个光在物体反射出去的能量叫radiance。 irradiance 为incoming radiance,表示入射的能量。
-
- 如何做shading? 渲染方程的积分怎么做?
-
- 光的反复弹射
5.2 简化的解决方案:主光源与环境光
对于ambient light的模拟,结合环境贴图,根据视角方向的角度,根据表面的法线向量进行反射,在cubemap中找到那个点。
5.3 Blin-Phong模型
体现光的可叠加原理: Ambient + Diffuse + Specular
所有的光不管来自什么地方,最后都可以线性叠加在一起。

问题:
-
- 能量不守恒
-
- 与真实世界偏差较大,塑料感强
5.4 ShadowMap
算法流程:由光源渲染场景,得到相机到光这个点的距离,去做正面的相机位置渲染的时候,每一个点我通过反向投影,把你投影到那个光源视角的Projection的位置,我也可以得到一个距离,如果这个距离大于最近遮挡物的距离的话,那就在Shadow中;如果等于或者小于的话,就不在Shadow中

5.5 Spherical Harmonics
5.6 LightMap
把整个场景的光照预先算好烘焙到一张图上
利用5.5 进行几何的简化,要在参数空间进行分配,我们尽可能希望在同样的这个面积或者体积里面,给到的这个Texture Resolution(Texture的精度)
生成UV Atlas, Lightmap density
缺点是
- 非常长的预计算的时间
- 其次它只能处理静态的物体和静态的光,当你的物体一旦变了、光源动了,以前烘焙的内容就全部完蛋了,但是动态物体确实是有办法Hack的,在做一些简单物体的时候,可以从周围去Sampling一个点上的Lightmap,就可以猜到环境光长什么样子,这时候我给他一个光照等等
- 第三个缺点是既然这是一个空间换时间的策略,那么Lightmap本身占用几十兆到100兆左右的存储空间,这取决于场景的大小
5.7 LightProbe
算法极其困难,这里来个简单粗暴的,在空间上撒一堆的采样点:Light Probe,每个点上的光照就是一个半球、一个Probe,那就放置一堆Light Probe
现代游戏一般采用自动化生成,对空间的几何
5.8 ReflectionProbe
Light Probe采样的时候一般我们会采样的比较密,我们可能会用到一些压缩算法,比如说把精度压得非常的低,因为我们只要用它来做光照的话,光照如果只做Diffuse的话其实可以非常的低频,这个地方用Spherical Harmonics压缩也没太大的问题,但是游戏中会有很多光亮的东西,它走在这样的环境中,反射的内容会经常发生变化,所以有时候我们会专门做一种Probe:Reflection Probe
5.9 Probe 总结:
把【Light Probes(处理动态)】和【Reflection Probes(处理静态)】放在一起的话,就能够实现一个还很不错的GI的效果
- Runtime首先也是非常快的
- 它能够处理静态物体和动态物体
- 其实是可以在Runtime时候可以更新,如果这个场景发生了变化,人物发生位置上变化,实际上现代计算机上Light Probe是可以Runtime更新的,这其中有一个细节,我要去做Light Probe需要放一个相机,向上下左右观察,把周围拍6张照片,拼成一个图,拿到这个图之后,我再用我快速的GPU Shader对它继续各种处理,速度也会非常的快
缺点呢就是比不上Lightmap,因为他能给你场景中动的物体,非常好的光照感,环境也有这种感觉,但是环境无法像Lightmap那种非常软阴影的感觉、物体之间交叠的感觉,包括一些非常漂亮的Color的效果做的也不是特别的好,这就是因为你的采样太稀疏了,Lightmap在地图上要采样几百万个点,Light Probe几万个不得了了,所以其实Light Probe是Lightmap几百分之一的采样率肯定是达不到人家的效果的。
5.10 BRDF模型
GGX模型,光打到物体表面的两件问题:
-
- 模型表面将光弹射了回去,至于能弹射多少取决于模型,表面的这个法向的分布,就是Roughness这个粗糙度,如果法线比较散乱,那么彼此之间就是发散,可以看到高光很发散。这部分是Specular
-
- 但是还有一些光会射进物体里面,如果是金属,金属的电子可以捕获这些光子,那些电子就会将光子笑纳;如果是非金属,电子就没有能力捕获这些光子,这些光子就会在内部来回弹,以一个随机的方向射出,相当于一束光,射到物体表面,在其中发生了几次折射之后,全部散出去。这部分是什么呢?就是Diffuse

- 但是还有一些光会射进物体里面,如果是金属,金属的电子可以捕获这些光子,那些电子就会将光子笑纳;如果是非金属,电子就没有能力捕获这些光子,这些光子就会在内部来回弹,以一个随机的方向射出,相当于一束光,射到物体表面,在其中发生了几次折射之后,全部散出去。这部分是什么呢?就是Diffuse
-
漫反射 diffuse的部分,这部分非常简单,如果你把球面上所有的漫反射的部分积分,积分起来的话,就是一个PI分之C,C取决于你的这个多少部分的能量传入进来(计算导出的话需要微积分的知识)
-
反射 specular的部分,引入了著名的【CookTorrance模型】,【CookTorrance模型】的数学公式看起来就很漂亮,有著名的三项:DFG,每个字母代表了一种光学现象
CookTorrance模型- D项:

// GGX / Trowbridge-Reitz |
引入了Roughness,表达了你的法向分布的随机度,Roughness越高,随机性越强;Roughness越低,随机性越弱,就越聚集,像一个镜子,有了随机度就可以得出另外一个部分
CookTorrance模型- G项:
Geometric attenuation term(Self-Shadowing),微表面几何内部的内遮挡

比如说一个光100%能量射进来,根据Normal Distribution Function、就是模型的Roughness,我知道有比如30%的光被遮挡了,那我知道剩下的是70%,这些光是无数的光子,开始往我眼睛里去跑的时候,因为这个分布是各项同性Isotopic,又有70%中的30%被干掉了,所以最后流到眼睛中的是49%的光,就是这个原理。公式巧妙的地方在于,我们在计算Normal Distribution Function的时候引入变量a的时候,又完美的直接用在了G项中,就只需要设置一个参数Roughness,就可以得到两个结果
// Smith term for GGX |
CookTorrance模型- F项:
Fresnel Equation
当眼睛非常接近表面的切线方向的时候,反射系数会极具的增加,这时候就会产生倒影的效果。

float3 F_None( float3 SpecularColor ) |
所以大家发现【CookTorrance模型】这么复杂的一个反射方程,实际上只要用
- Roughness一个参数
- 再加上一个Fresnel参数(F0)
5.11 Disney 信条

- Specular Glossiness 模型
几乎没有什么参数,所有属性都用图来表达

太灵活了特别是Specualr的RGB通道,美术一旦设置不好,就会导致Fresnel项炸掉,那项叫F0,那一项一旦炸掉材质就会非常奇怪,所以在工业界,后来想到了一个“土法炼钢”,叫做【Metallic Roughness】
- Metallic Roughness 模型

可以理解为【Metallic Rougness 模型】是在【Specular Glossiness 模型】外面包了的一层,类似写了一个通用函数,但是通用函数很多人会用错,用不好会把整个操作系统搞炸掉,那在外部再包装一层小白用户指南,只允许几个开关,开关变少之后,但是会保证所有的参数都是有意思的,这样我的系统就不会炸掉,MR模型的核心思想就是这个
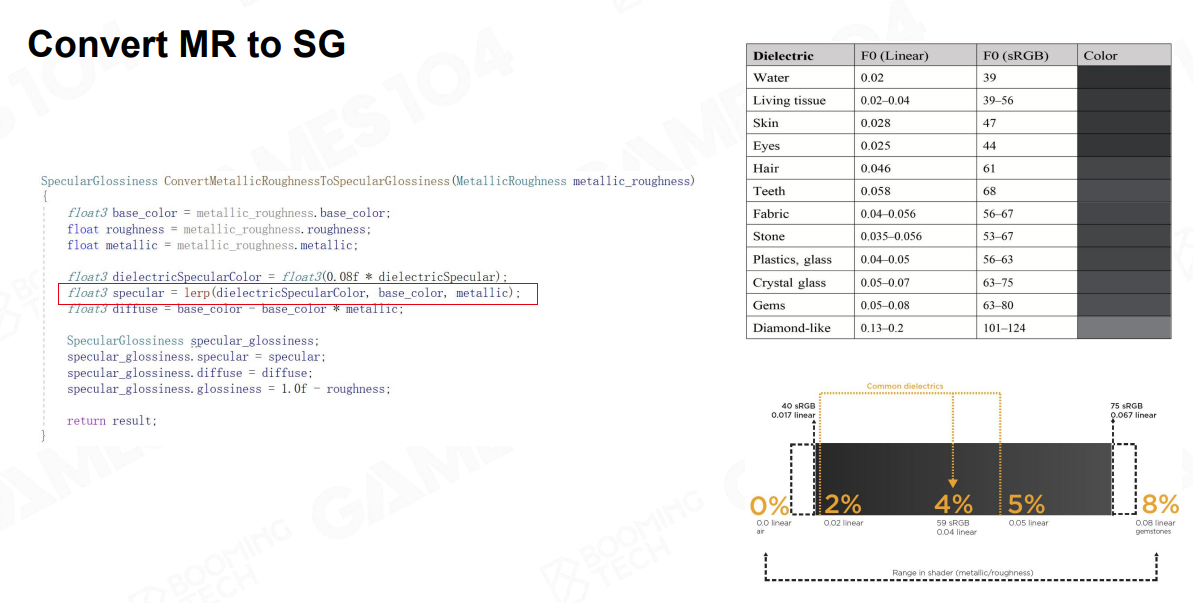
其中有一个Lerp函数,就是根据Metallic的数值:
- 如果是非金属的话,就把它直接锁死,那个数值很低大约是在0.02~0.3之间,Specular只能这么多
- 但是如果是金属的话,就逐渐的从BaseColor里把这个数值取出来
美术方面虽然灵活度下降了,但是它不容易出错,所以在行业实践中,很多会倾向【MR材质】而不是【SG】,这也是Disney 信条了不起的地方,当你管理上百人的团队制作游戏的时候,可控性反而是非常重要的,所以学习时,应先学习【SG模型】,再学习【MR模型】,这两个模型,基本上够用了,Unity和UE也是这么实现的
坏处,当你在非金属和金属之间过渡的时候,会容易产生一个小小的白边,这个可能注意不到。MR模型总体来说更加符合直觉,也不容易出错,这就是PBR的材质模型的介绍,下面有MR模型与SG模型的优缺点介绍
5.12 IBL (image-based Lighting)
- IBL最核心的想法是什么呢?
如果我能够对这个真实的这个环境的光照,做一些提前的预处理的话,是不是就可以快速的把它整个环境对我的光照,和我的这个材质的卷积运算,直接计算出来
IBL的思想,这个材质思想也很简单,就是看我们的这个材质模型,就两部分组成:Diffuse + Specular.
Diffuse部分观察起来非常简单,就是Cos函数在球面的分布。对于任何一个比如说法向的朝向点,给定一个光照的时候,可以计算出这个面,和这个球面上所有的点,进行积分之后,用Cos Loop进行积分之后,它的值是可以提前计算好的,就可以提前计算好一个叫做Diffuse的这个的卷积的结果,这个图叫做Diffuse Irradiance Map,当我知道了环境上这样一个漂亮的一个光照的时候,我知道它的Diffuse部分,无论这个表面上的法向怎么转,比如说以身上衣服为例,一条光照射过去,选择一个方向去采样Diffuse Irradiance Map我就知道和整个光场卷积的结果是什么
-
Diffuse Irradiance Map
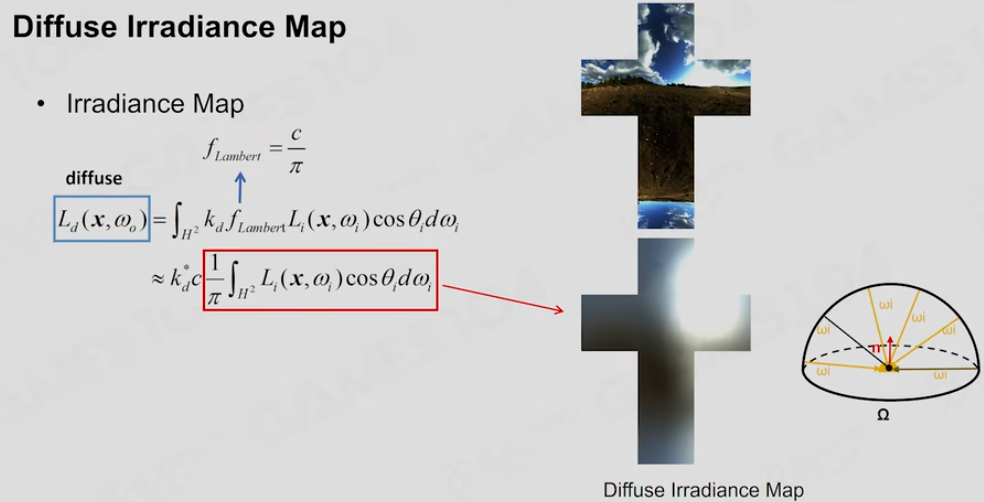
这个思路也是空间换时间,先计算好了卷积结果,记住就可以了。之所以重要是因为空间中的光场采样,比如说采样一个32x32,也就是几万个点,卷积计算用硬件加速是非常快的,但是当我去渲染这个游戏引擎画面的时候,实际上屏幕上是几百万甚至上千万的像素,而且每一帧都要做,每秒要做30次这样的运算,运算量非常大,所以这样的话,这部分计算如果用一张小的计算Texture,其实是预先计算好的,可以理解为一张计算表,查表就可以知道它的卷积的结果的话,速度将会快很多,这就是IBL最简单的思想 -
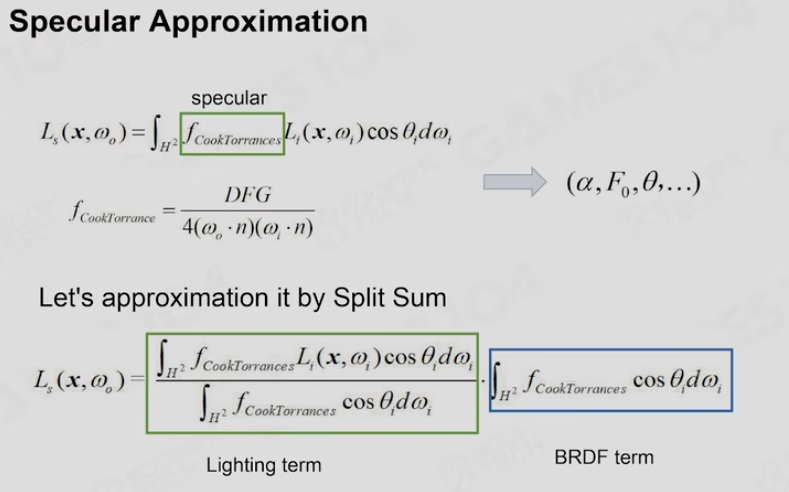
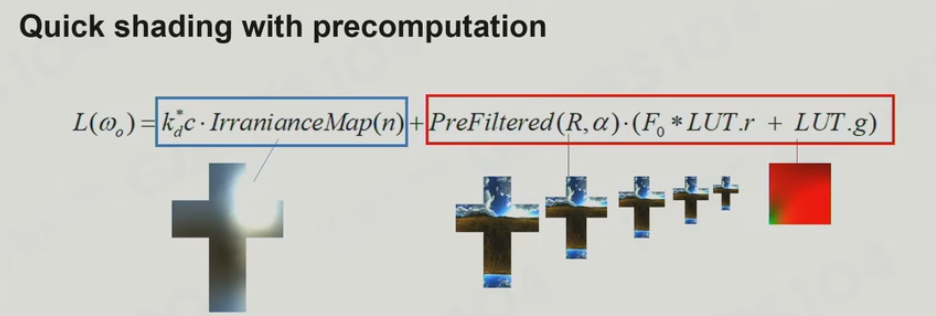
Specular是非常复杂的,推导过程中,对Specular的解决方法做了大量的假设,本质上是三个方程乘法的积分,它变成了三个独立的方程的积分的乘法,最核心的想法是我们把Specular的东西进行沿着自己朝向积分,但是有一个变量Roughness,不同的粗糙度计算出来的结果不是不一样的吗,它有一个巧妙的方法就是利用硬件上的Cubemap中的Mipmap的功能,他把不同粗糙度的结果,存到了这个Mipmap的不同层级,即如下图右侧。这个是非常有道理的,相当于在三维空间中去查这个数据,第二个是,粗糙度越是高,对光照的敏感度也就越低,他就是越低频的数据,就可以放置到Mip的最低级(注意这里的Mip不是Mipmap二合一合出来的,真的是每一层都要单独计算出来的),而且实际上是一个速算表,Roughness从0到1的时候,就可以在里面迅速的去检查

还有一个值,学名叫做Look Up Table(LUT),LUT有两个维度,一个还是Roughness往里面放置,另一个是斜角Cos角与环境的关系

利用这两个数值合在一起,就会发现它的Fresnel项变成了一个线性项,就能够基本上模拟【CookTorrance】这样一个在环境光照下的效果,所以这个IBL对Specular的解决,做了大量的假设之后给了一个近似的解,优点在于
这种近似让我们能够在这个环境光照中,看到一些高光的内容,注意这里的高光不是非常Shiny的高光,那种其实用Cubemap就能够解决,它是真的让人感觉这个地方好像有一点光亮,但又不完全光亮,并且能够模糊的让人感觉那边有内容
5.13 经典Shadow解决方案
- Cascade Shadow Mapping(CSM)
shadow map的精度问题对于宽阔的场景来说非常头疼。因此对于shadow进行分层。
远处的Shadow就算有一个边界的话,投影到你的眼睛的话,相对来讲实际上也并不是特别的大,近大远小,远处的位置眼睛采样率也会下降的,从光的方向的采样率也下降了,两个部分就完美的配合在一起了,这就是【Cascade Shadow】一个简单的想法
Cascade Shadow有一个经典的挑战就是在不同的层级之间,要做插值否则回出现一条非常硬的边界,如果这里不做任何事当你相机移动的时候,有个固定位置Shadow会破掉,具体的处理都是Shader中的Hack,所以当认真写这些算法的时候一定要认真的研究几个不同的方法和套路
Cascade Shadow的问题呢就是以【空间换时间】,存储空间是挺大的,另外就是说要生成远处的Shadow,相当于将整个场景绘制了一遍,那个时候你要画大量的东西,成本不低,Shadow Rendering其实是游戏引擎里最贵的独立的一派,他并不是你真正绘制的那种精致材质的组成部分,它只是确保光的可见性是正确的,但是如果我们绘制假设是30ms的话,Shadow很多时候会吃掉4ms,所以Shadow是非常expensive的,要绘制四次,对场景做四次的这个裁剪,因为你在绘制那个最密集的Shadow的时候,你并不希望它画很多东西,其实你要重新计算一次Visibility,再去计算,这其中就有一堆的问题在其中
- 软阴影
- PCF:Percentage Closer Filter,使用滤波的方法, 实战中使用PCSS(Percentage Closer Soft Shadow), 很大程度缓解了Shadow的这个Alias。
- Variance Soft Shadow map, 用平均的深度(一次方二次方)算出方差,近似得出深度的分布
5.14 总结:
AAA级游戏的渲染引擎(5-10年前):
Lightmap + Lightprobe
PBR+IBL
Cascade shadow + VSSM
5.15 前沿技术:
随着硬件的飞速进步,实际上几乎是彻底颠覆了渲染的底层方法和逻辑,因为它把整个底层的计算全部开放出来了
- 实时光追: 解决的问题不至Specular、ReTracing,实际上会彻底改变我们的光照体系:Real-Time Global Illumination,Lumen效果其实就是硬件的效果解放了出来
- 最高效的ScreenSpace GI,在屏幕空间快速的形成GI
- 包括基于有效距离厂的SDF做的GI
- 包括把这个世界分成各个Voxel,最著名的就是SVOGI、VXGI
- Reflective Shadow Map、RTX GI
-
复杂的材质渲染
BSSRDF, BSDF(Stand-based hair)
Geometry Shader技术的发达,可以迅速的生成无数的细节,光影效果会做的非常复杂,3S材质可以用这种强大的算力,可以模拟光在材质里的Reflection的一些数学结果 -
Virtual Shadow Maps
传统的【Cascade Shadow】挺好用的,UE5提出了Virtual ShadowMap,之前John Carmack大神提出过【Virtual Texture】,把游戏环境中所有要用到的纹理,全部Pack到一张巨大无比的纹理上去,这个纹理就叫做Virtual Texture,要使用的时候就把他调出来使用,不用的时候就把这些Texture卸载/Offload掉
5.16 Uber Shader and Variants
对于shader的管理,为防止过多的shader文件,设置不同的分支和变体,生成shader.
Uber Shader,我们一般会使用宏定义,去把各种情况给分出来,每一种宏定义就代表了函数的一种可能的分支,之前提过GPU里面最讨厌的就是分支,因为比如说一个函数跑起来,他有一个分支的时候,就会导致它的执行的时间长短是不一致的,但是GPU采取的是SMT的架构,它希望我1P指令扔出去的时候,结束的时间最好是一致的,所以我们就会把这些所有的分支,编译成铺天盖地的Shader
那为什么Uber Shader是有道理的,因为你想期望的Shader,假设今天发现了一个Bug,需要改一类Shader算法的时候,如果不采取Uber Shader的方式的话,需要逐次的改它所有可能的组合,这就很可能会改错,但是用Uber Shader这种方式的话,就自动编译出了各种组合,所以它是有道理的,这些Shader都是其实是现代游戏引擎非常重要的一个方法论和概念
在做shader,需要考虑好平台性,编译到各个平台。
6.地形大气和云
6.1 HeightField 高沉图
一种简单的方法对地形进行模拟的方法是使用高沉图(Heightfield),Heightfield 记录了地形的高度数据形。
现代地形渲染的主力。
- 使用 Heightfield 进行地形渲染,主要是将地形进行均匀的划分,并将每个 网格的顶点进行高度的位移即可,但缺点在于不适合用于构建复杂的地形。
- 因此需要使用到LOD技术和FOV参数。 FOV 是地形细分的一个重要的参数,若 FOV 的角度变窄,三角形的密度会越来越高,即:在屏幕上看到的效果会将 FOV 中的地形放大(如:游戏中的倍镜)。
如果屏幕在同等像素量的情况下,每一个三角形在 FOV 越小的时候,所占据的像素越多。
6.2 三角形剖分
永远将三角形的最长边二分,成为两个小的等腰直角三角形,也叫二叉树三角剖分
这个方法会出现一个问题——T-Junctions(T 型裂缝),即:不同层级的交界处,更高 LOD 的顶点没有对应低 LOD 的边,由于地形该地不同二出现裂开的现象:
解决方案: 如果相邻三角形的切分更密且当前三角形没有可以对应的边进行衔接,则将当前的三角形也进行切分,直到不会出现 T-Junctions 为止
Unity 在 GPU 上使用 Triangle-Based Subdivision 可以绘制出 54 x 54 km 的地形,但是这种方法不符合制作地形的直觉,因为对于大型的地形,一般会考虑使用分块的方法进行管理。
6.3 基于四叉树的细分
目前最主流的地形数学表达方式
对于三角形剖分的问题,使用四叉树的细分方法。
基于四叉树的细分方法(QuadTree-Based Subdivision)将地形划分为不同的 Block (Messiah 里面则是 Chunk),每个 Block 里面通常包含 4 个 Quad (一个 Quard 可以是 100 m x 100 m 等),通过这样表示地形的数据,是很符合磁盘存储数据的规范
T-Junctions的处理方法:
“吸附”的方法,一边多出来的中间点直接吸咐到另一个少点的边上。
假设两个 Quard 连的很近时由于细分的级别不一致,可以采用动态模式缝合 的方法(应该也可以叫强制对齐),通过调整三角形为退化三角形,而达到缝合边界的效果:
- 蓝色的 Quard 多出来两个分割点,将其分别 Stitch 对齐到右侧橙色 Quard 的左上方和中间的顶点处(也可以都吸附到左上方);
- 被移动的两个分割点和橙色的 Quard 左上方顶点构成一个面积为 0 的三角形,即:退化三角形;
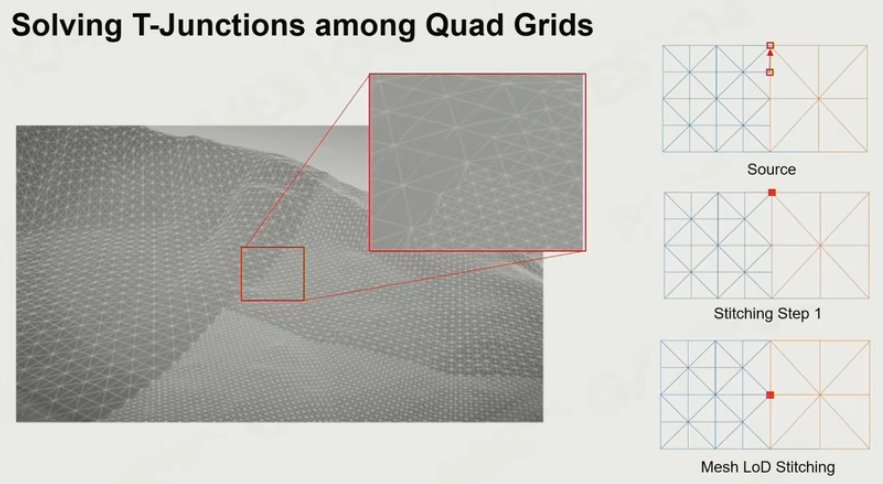
6.4 TIN
使用不规则三角形(Triangulated Irregular Network,TIN)的方式表示地形,对于一些类似沙漠的有很多比较平缓地势,特征顶点较少的的地形而言,可以通过简化面片的方式对地形进行建模。该方法的特征在于:
- 不规则三角形网格的建模需要进行预处理,且在 Runtime 下不好调整;
- 好处在于在很多请路况下使用该方法绘制的三角形比上述两种方法少。 因为从信号的角度看,TIN可以针对比较多信号的地形进行不同的采样。
6.5 GPU-Based Tessellation
-
- Hardware Tessellation
Hull-Shader Stage 可编程,操作人员设定细分的操作与数量。接收控制点信息,与一些系数发送到 Domain Shader, 同时发送一些系数到 Tesselator。可以指挥 GPU 如何对顶点进行曲面细分操作,但是还未具体执行细分。
Tessellator Stage 不可编程,由硬件管理,GPU会根据 Hull-Shader Stage 阶段对曲面细分的指令,执行曲面细分,这个阶段才是真正的曲面细分执行阶段。
Domain-Shader Stage 可编程,设置新生成点的信息并转换到匹配的空间。将所有接收到的信息整合,可以控制计算经过后面的Geometry shader曲面细分后的顶点。

- Hardware Tessellation
-
- Mesh Shader Pipeline - DX12+(win10以上)
一个Mesh Shader包含了将前1的Vertex shader到后面的Geometry shader的一个流程
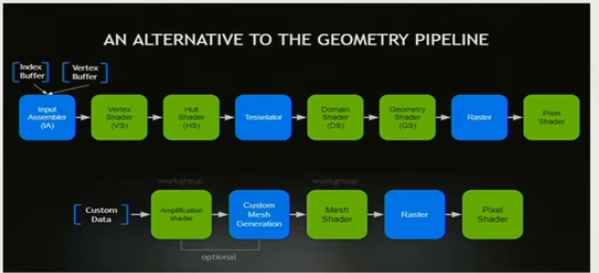
- Mesh Shader Pipeline - DX12+(win10以上)
6.6 可变性地形
实现Real-Time Deformable Terrain,如车路过地形变化的效果。
如雪地,相对爆炸坑较易做,高度不变因为不需要改变物理碰撞。
6.7 其他构建方法
- Dig a Hole in Terrain.通过在地形上删除掉一些面,挖洞的方法。
- 体素化:Marching Cube 通过一个个面的切分
对地形进行体素化建模是指:在三维空间中,对地形进行采样,并在这些采样点上存储权重值(如:0-16),用于表示该采样点物质的密度。在二维空间中,可以使用像素表示 一个影像,在三维空间中就可以使用体素的三维数据表示一个栅格化的三维空间,可以根据其存储的权重表示该体素是空心还是实心。
6.8 地形材质
材质混合
-
Simple Texture Splatting
地形的材质混合,需要制作地形的 Base Color Map、Normal Map、Roughness Map、Height Map,同时还需要一张 Splat Map 混合贴图,该贴图每一个通道对应一种材质的权重,可以在混合贴图上绘制不同的笔刷,即可混合不同的材质:
· 存在问题:
两种材质过渡的时候,如果简单地采用 Alpha 混合的话,会出现一个相互重叠地区域,这样的表现十分不真实,而真实的情况是两种材质相互交叠显示。解决这个引入了Heightmap -
Heightmap - Advanced Texture Splatting
使用 Height Map。在两种材质过渡中间,将 Height 根据权重进行比较,如果权重更高,绘制的权重就下降慢一些,Height 低的则很快削减:
· 存在问题:
由于两个材质切换的地方是 0-1 切换,当角色在移动时相机的位置会是一个高频变换的情况,此时地形材质的分界线会很明显。 -
Biased - Advanced Texture Splatting
扰动,在中间区域,通过biased做颜色混合 -
Texture Array
地形材质非常多的情况下,选择Texture Array
使用 Splat Map 的方式对地形材质进行混合是一种比较局限的方法,因为在真实世界中,地形的混合不止 3、4 种,因此需要使用 Texture Array 的方法。Texture Array 将所有的颜色纹理打包为一个 Array,采样时只需要通过 **Index( 索引)**进行采样即可。这很好地解决了地表材质的表示,因此在绘制地表材质时,Splat Map会存储权重和使用材质的 Index,最后根据这些 Index 对不同的贴图进行采样 -
Virtual Texture
只需要把用的资源装到缓存,由于 Mesh 的 LOD 技术导致了可以给不同 LOD 烘焙贴图的解决方案。

一个很大的 Texture 将不会全部加载到内存中,和虚拟内存是类似的,就是把不用的不放到显存里,只把用的放过去。如:屏幕为 1024 * 1024 分辨率,而这个巨型贴图为 (1024* 16)(102416) 。在屏幕显示时,可以把纹理缩小到屏幕可以装下,一个像素装 16 个纹素,但只能显示一个颜色。因此,多出来的 15 个纹素就是没有用到的。
另一种方法,就是给这个巨型贴图,做 mipmap,将其转化成 边长为原图的 1/16。此时,一个纹素就可以对应一个像素,运行时只加载 mipmap 之后的图片即可。
再一个场景就是,这张图片放的很大,而屏幕中只能看到一部分,此时不需要将整个问题加载到显存,只加载屏幕中看到的那部分区域即可。
6.9 地形绘制的精度溢出的问题
解决办法:Camera-Relative Rendering—相机相对渲染
一般物体都在世界空间,将所有的物体坐标转换到相对于相机的位置,即:将相机设置为 0 即可(虚幻、Unity)。

6.10 辐射方程
Radiative Transfer Equation (RTF)
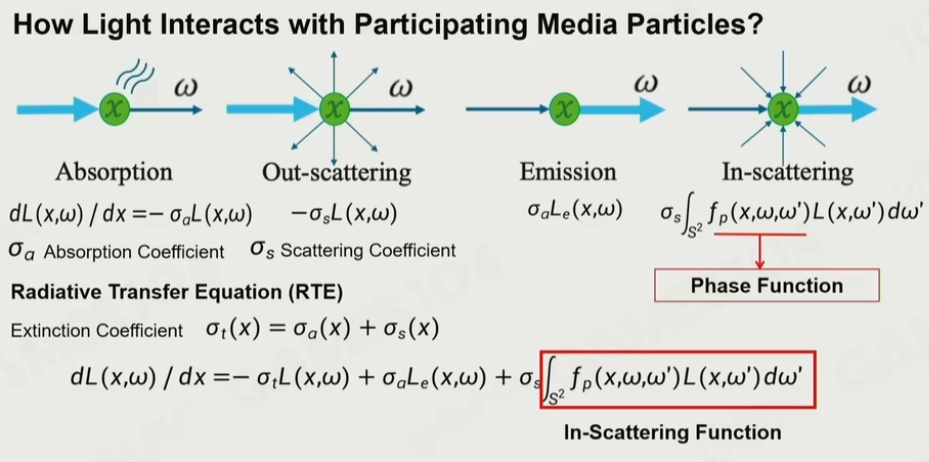
由吸收+自发光+散射光积分组成
- 光束射向介质的时候,介质会吸收一部分光的效果,而光在传播时,每往前照射一个单位时,会被介质吸收的部分是一个常数:σα
- 光在和粒子发生接触时,会向周围散射,也是一个常数:σs
- 有时介质通常还会带一点自发光,而自发光的计算可以表示为:(可选),如火焰等
- 介质粒子还会受到周围粒子的散射光影响,可以表示为一个关于球面的积分,即对整个球面所有来自其他介质的散射光的积分。
6.11 体积渲染方程
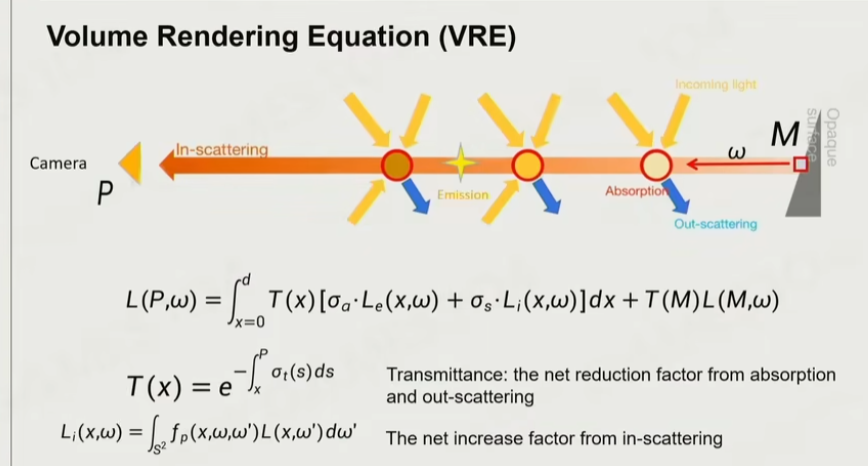
当相机位于 P 点,看到的东西由:从 M 点,依次一个一个去计算光线被吸收的部分、被散射的部分、其他散射的光又与之交互以及自发光构成。主要有两个部分:通透度(Transmittance)——在M点看到的东西(如:蓝色)大概有多少会保留到在 P 点看到,是一个路径积分的结果。散射方
(Scattering)——在光线传播过程中又叠加了其他粒子的效果,也是一个沿着路径的积分。
如果已知通透度、散射这两个部分以及光场信息,即可以计算出,从 P 点看到 M 点应该是什么样子的,这就是著名的体积渲染方程(Volume Rendering Equation, VRE)。
其实,RTF 就是对 VRE 的积分。因此,通透度和散射是体积渲染中的两个重要参数。
6.12 Rayleigh Scattering Distribution

当太阳直射时,大量的蓝光会被大气散射,多次散射之后进入眼睛;而红光的散射较少,所以可以看作是直接照射到地上。因此,看向天空时蓝光会四处散射,而到了傍晚,由于光线角度的原因,蓝光会往大气层外面散射,因此蓝色会减少,红色变多。
λ 光的波长,表示波长越短时,散射系数越高
θ 光与介质之间的夹角
h 海拔高度
N 标准单位的体积密度
6.13 Mie Scattering Distribution
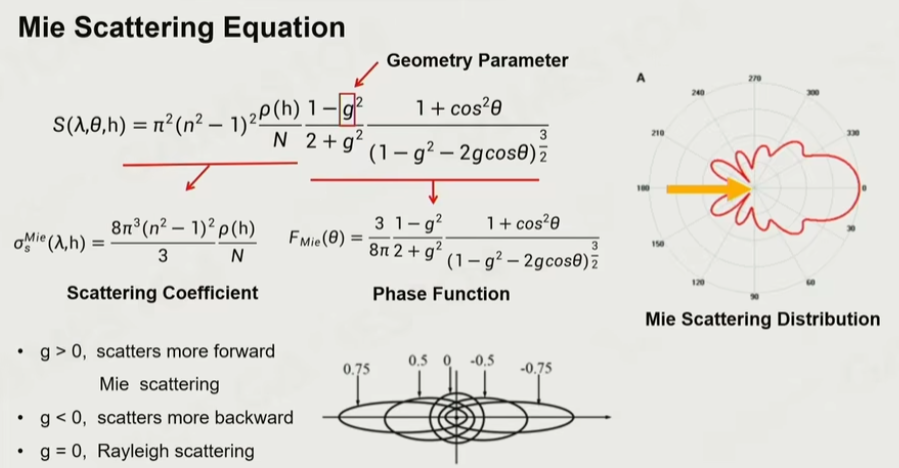
米氏散射对波长不敏感,具有方向性。
米氏散射中最重要的效果就是雾效,所有的太阳光照射下来进行无差别的散射,因此雾看起来是白色的。同时,日晕的产生也是米氏散射的原理,由于米氏散射带有方向性,因此可以在太阳周围可以看到光晕的效果。
6.14 Ray marching
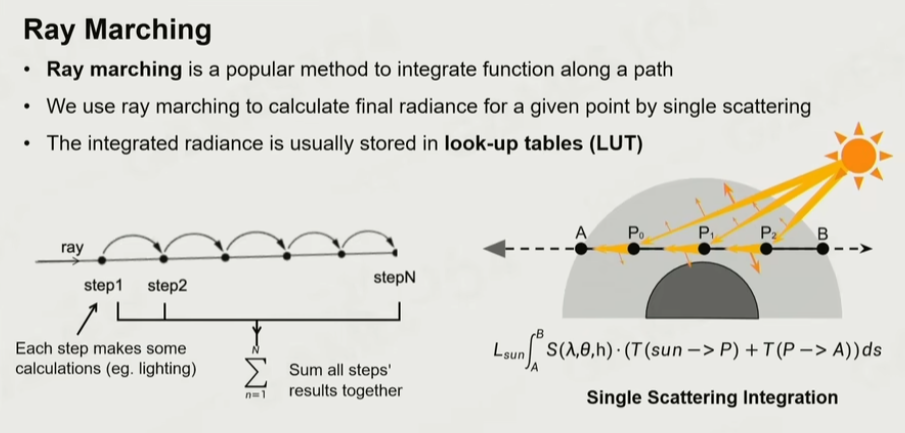
沿一条射线直接积分下去
即:沿着一条视线,把沿途的效果一步一步进行积分。对于单次散射而言,沿着视线方向均匀采点,计算太阳照射到采样点的强度和方向,根据散射方程计算瑞利散射和米氏散射,沿路积分下去即可计算出单次散射。
6.15 实时大气渲染
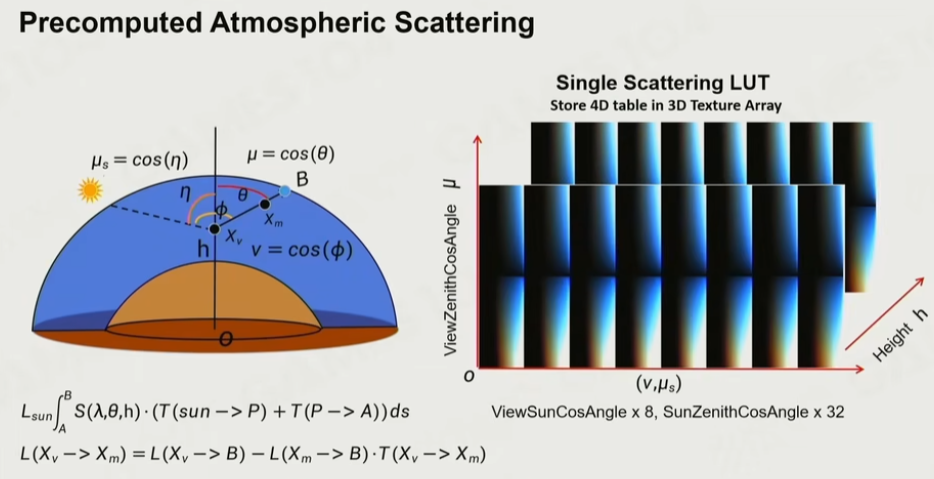
LUT 查询表
Precomputed Atmospheric Scattering
-
通透度
以上方法大都采用以空间换时间的解决方案,而预计算是预先计算大气的通透度和大气散射,这里使用remarching方法 -
散射
参数化思想,首先在海平面高度 h 的地方朝某个方向看,会得到一个天顶角 θ。然后,可以计算出太阳与天顶的角度 η。以及,太阳和视线的夹角 ϕ。这三个角是三维的角度,而大气是各向同质的,因此,只需要存这三个角,即可计算出所有从当前视角看向太空所有点的沿途的散射值。最后,沿着高度进行采样,可以得到一个四维表。
有了通透度的分布图、单次散射的分布图,利用空气中的点,再次通过通透度进行积分,可以得到二次散射的分布图。理论上,可以得到无限次的通透度分布图,但一般3-4次就够用了。得到了多次散射的 LUT 之后,即可通过预计算的方法进行查表。
问题及挑战:
- 预计算的成本:多次散射的迭代是非常耗的,在低端设备上很难生成一个大气的 LUT
- 环境的创作和动态调整:美术不能动态改变散射系数,难以渲染如:从晴天到雨雾的天气、行星间的太空旅行等效果
- Runtime 的渲染成本:在通透度 LUT 和散射 LUT 上逐像素多高维纹理采样成本很高(始终需要下采样以提高效率)
6.16 云
层云、层积云和卷积云
-
方法一: Mesh-Based。
优点,质量高。缺点: 消耗大,不支持动态天气 -
方法二:Volumetric Cloud Modeling
体积云是一种常用方法,该方法渲染出来的云可以实现很真实的云层效果,是一种全动态的算法。该算法使用一种 “Weather Texture“的贴图,存储了云在空间上的分布+云的厚度 0-1,通过调整这个厚度通道的值,可以改变云层的厚度。如果需要实现云层的飘动,可以将这个贴图进行平移,以及添加扰动实现云的形态变化。
优点: 多变,接近现实,动态天气
缺点: 算法复杂,且效率性能的问题
使用Weather Texture, 使用Noise Function生成噪音。
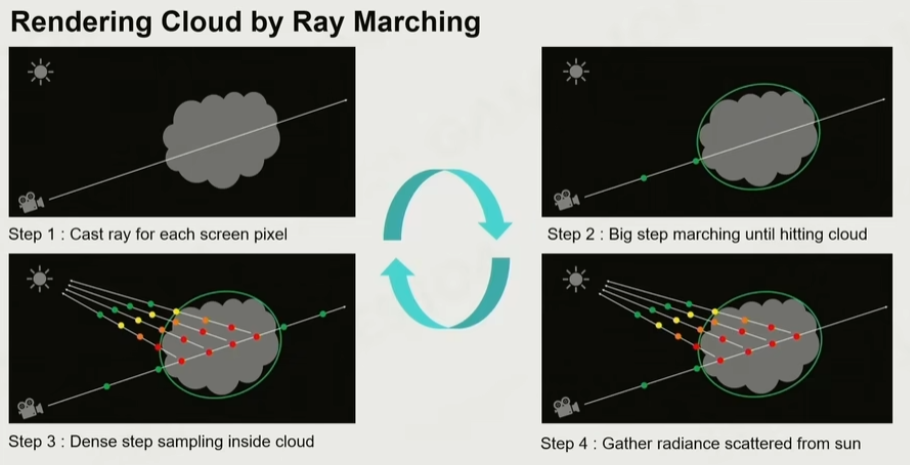
渲染云:
云的模型生成之后,需要对云层的锯齿进行优化,使用 Ray Marching 的方式可以对云层进行渲染。当视线接近云的时候,将采样的步长变小,直到离开云的边界,然后计算大气的通透和散射即可。在云里面计算通透和散射更加简单,因为云一般通透度都不高,因此可以对方程进行简化。
6.17 噪声
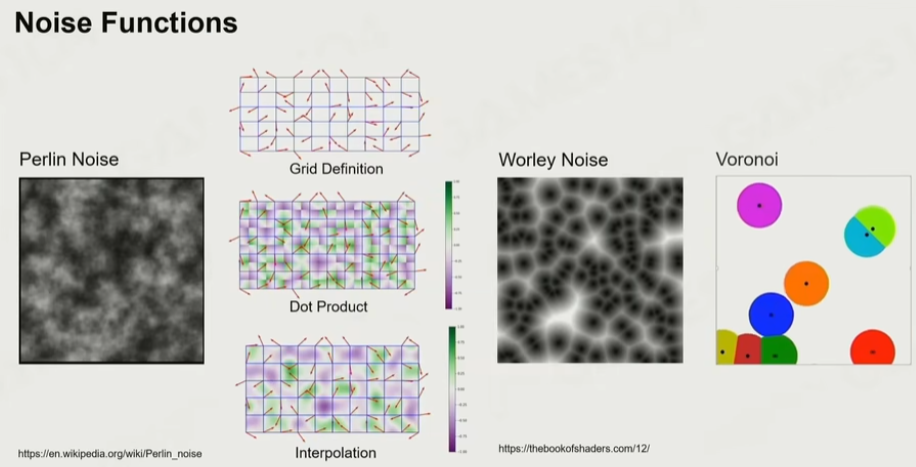
著名的噪声包括:柏林噪声(在一个多项式的时间内可以实现类似棉花絮效果)、Worley 噪声(Voronoi 空间分割,可以形成泡泡絮的效果)。
7.渲染与后处理
7.1 AO-Ambient Occlusion
环境光遮挡剔除 - 实际上决定了一个明暗关系,可以看到非常清晰的结构和空间感。
- 数学原理刚才也提到了,对于表面上的每一个点,在它可看见的正半球面的话,他只有部分可以看见天光,有些部分被它周围的几何给遮挡住了,所以就会产生了AO的效果
这个有点像之前介绍的【CookTorrance模型】、就是BRDF,表面上有很多小面片,他有一个选项叫做Geometry,它叫做几何的自遮挡(下图我补了一句“Geometric Attenuation Term”),实际上把相机拉的足够远的话,AO所表现的数学方程的话,你会发现和BRDF是非常接近的,所以尺度是相对的,取决于相机的远近
-
早期做法: Precomputered-AO, 预计算AO
还是不能被取代掉,因为我们的AO计算都是基于你有几何的,如果你的表面没有真正的那些小的结构的话,即使是RealTime的算法我也是计算不出的,所以这个方法在很多Character角色表达的时候,这还是一张很重要的图。如果大家画一个角色的时候,AO这场图一般是会出现在你的资产中。 -
那如何解决环境的情况呢? 这时就需要SSAO - Screen Space Ambient Occlusion
思路: 相机渲染场景过去,就会得到一帧场景图像,一帧图像我们看到的是RGB颜色,不止这些,还有它的深度信息,如果我们把每个像素的深度信息连接到一起的话,就会是一个Height Field,那知道了Height Field,实际上就是一个几何,我就可以估算这个Height Field对各个区域的自遮挡的关系如何
明细:
从眼睛射出去一根光线,交汇到了我看到物体的任何一个点,我能知道它在三维空间中的XYZ坐标,那么给它一个半径,在半径周边随机在球型空间中,随机撒若干个采样点,若干个采样点再用相机去投射,这样就知道它的深度
- 如果这个采样点的深度,相比较ZBuffer中的深度更近,那么说明这个采样点是在可以看得见光的地方
- 那如果我这个深度比ZBuffer中的更远,说明它一定是被当前绘制中的某一个几何给遮挡住了
这其中有一个很重要的思想就是ScreenSpace,虽然我们在游戏中,对整个世界有一个完整的几何表达,但是在做很多运算的时候,我们如果真的把上万个物体,上百万个面片,做各种几何运算,效果是非常低的,后来大家发现,由于我们有了深度信息,我们在屏幕上只是对一个局部的几何采样信息,用这个局部的几何采样信息其实我们可以做很多的运算,所以SSAO就是运用了这个原理,包括之后介绍的ScreenSpace ShadowMap、ScreenSpace Reflection,ScreenSpace GI,这些概念都是从这个原始思想出来的
-
SSAO+
当人们意识到SSAO最古老的采样方法是多余的,因为只需要采半球面之后,就引入了另一个思想,如果我们知道法向朝向,我只需要沿着法向,采半个朝向,采样点少一半,并且能解决刚才的问题 -
HBAO
想计算出在球面空间上的可见性,实际上从这个点出发,沿着各个方向转,去找一个光线能够越过最高几何的这个Pitch Angle。如果那个山距离我太远了,我认为它对我的AO没有什么变化(就是上面提到的Artifact),距离如果设置的比较短的话,公式中的W就变成了0,所以就不会说距离很远的物体,还显示产生AO信息。
具体做法:实际上用的是【Ray Marching】的算法,一个像素一个像素的找,当然他有一个步长,不是一个一个像素,但是它会从那个点出发,不过他在每一个点会Jitter一下,因为如果每次找的方向都是一致的话,因为采样率很低,会出现一些很明显的Alias的花纹(类似信号与系统中,如果对一个信号的采样率特别的低,滤波器是非常规整的话,那么滤出的信号是有很明显的Pattern的),所以加了一个Hack,加了一个Jittering,所以在Pixel Shading中一步一步,沿着ZBuffer生成的那个Height Field,去找最远的拱角是多少,这样就可以找一圈,去计算出我的数值,这就是HBAO核心想法,是一个基于半球面积分的一个想法,比之前的SSAO的效果好很多,还能解决“Artifact”
问题:但是HBAO实际上还是有算法上很核心的问题的,之前我们介绍材质的时候,天空还是一个球,假设我的表面是朝上的,那从四面八方照射过来的光,天顶射下来的光,和斜角射过来的光,贡献值肯定是不一样的,之前介绍漫反射的时候有一个叫做Lerbert的模型,其中有一个很重要的Cos因子,你的光越是靠近天顶的时候,Cos夹角为0的时候,射出来的强度Irradiance是100%,散射的强度也是100%没问题,但是同样亮度的光从斜45°射过来,Cos45°约等于0.7,所以之前HBAO、SSAO+在计算球面积的时候,都没有考虑这个因素,所以他们计算的结果都是错误的。现在最多使用的是GTAO。
- GTAO- Ground Truth-based Ambient Occlusion
和用蒙特卡洛积分,非常慢的结果是一摸一样的,这是真的把表面的法线考虑进去了,这样就知道,当光线从各个方向来的时候,斜过来天顶的权重是会被打折的,天顶的面积贡献度是非常大的,这里理解这个思想就可以了
一种模拟的方法: 这个光线射进来之后,在其中来回Bounce(也叫做Multi-Scratching)最后形成的亮度是多少,真实情况下假设是一个山谷,光射到山谷的另一侧,在山谷底其实没有想象的那么黑,而且这个颜色,是和山谷周边的颜色有关,比如说山谷两边是红色和绿色,那么山谷底部是带色相的,听上去很复杂,需要做很多积分才能够得到结果,但是这也是GTAO中非常好的想法,如下图所示,它根据不同的AO值,对这个数值进行分析(类似机器学习的概念),AO值和Multi-Scratching值有一定的关联度,这个关联度当然不是一个简单的线性的,是符合了某一套曲线,并给出了一个多项式的方程,也就是说我们可以用一个多项式计算,根据现在的AO值,能够估算出光来回Bounce最终的结果
还有一个比较火的方向:Real Time Ray-Tracing Ambient Occlusion,Real Time Ray-Tracing数学基础核心就是现代GPU,可以快速帮助你做Raycasting的计算,告诉你到底有没有hit到,实际上可以对屏幕上的每个像素可以射Ray,让它知道和周围是否存在遮挡,这里有很多细节,这里不展开,如果想做对要在屏幕上每个像素点,它的半球面射出很多根Ray,但是现在GPU也没办法跑那么快,所以真实做法是在每一帧的时候,对于每一个像素,只对外射1-2根Ray,但是在时序上进行了数据的收集,这样就能够完成球面的一个采样的近似,关注这个方向的发展就可以了
7.2 FOG
- Depth Fog,Fog的原理一开始在游戏中非常简单,叫做Depth Fog,从眼睛看出去,随着距离【透明度】逐渐下降,会想到线性的方法,一般会设置一个起始点,特别近的地方我们还是希望没有Fog,逐渐后来Fog起来,到达远处之后达到一个最大值,但是实际上在使用过程中会发现,使用指数型Fog会比较好,一般会使用二阶的指数型Fog,这是非常简单,比如Unity的话就是这三种选项:
- Linear Fog
- Exp Fog
- Squared Fog
- Height Fog
计算机图形渲染中,Height Fog的假设是,当这个高度低于某个标准高度的时候,下面的所有Fog,都是最大的Fog值;当你的高度高于这个标准高度值时,我们认为Fog的强度,是指数递减的。
那么问题就来了,当我站在比标准高度高一点,去看高度内部的东西,看到的Fog强度应该是多少呢?
这个问题不是计算那一点的Fog能够计算它的Fog值,为什么不能用那个点计算是因为,假设那个点正好是Height Fog的最高点,从这个点到我的视角的浓度会越来越低,所以它不是一个简单的匀质的Fog,之前在讲大气的课程时我们提过,这种情况我们只能够Remarching进行积分,所以我们只能一步一步的积分,其实这个算法很早就提出了,那个时代不能对每个像素进行积分,所以做了一个简化,认为Fog Intensity对Fog的透明度是一个线性相关的,那么就沿着路径,只对浓度进行积分,计算浓度值,利用这个来计算透明度
Fog在游戏早期,几乎Depth Fog、Height Fog够用了,现代的话还有一个关注点就是【基于体素化的Fog】
- 基于体素化的Fog
Voxel-based Volumetric Fog实际上是将相机空间的整个空间进行Voxelize,这个”Voxelize“和之前提到的均匀的体素化不一样,空间中均匀的体素化就是一刀刀切过去,但是从人眼看过去的时候,近处的很多精度是不够的(颗粒度太大),但是到远处颗粒度又太细了,实际上产生不到你想要的效果;所以科学家想到,根据相机的视锥,以近平面、远平面,用视锥进行切分(如下图1的黄色线框),近处切割的非常密集,在这样一个不均匀的空间里面,进行各种ReMarching、Multi-Scratching的计算,这些计算和计算云、Sky的方法大同小异,上一讲我们介绍了计算大气的方法,把那个看明白这个也能看懂,思想是一致的,工程计算时会构建一个3DTexture来存储中间计算的结果
7.3 Anti-Anliasing
反走样
Aliasing本质就是屏幕的Resolution是有限的,而我们想要表达的几何世界的频率是非常非常高的
三种情况:
- 由几何导致的,几何的边只要不是横平竖直的话,在屏幕上一个像素一个像素的采过去的话,一定会出现这个效果
- 在这个物体表面有很多细节、Texture当从不同角度去观察的时候,这个Texture就会产生各种各样的Artifact,就是中间图的[摩尔纹],但是这个的问题之前的Mipmap解决了,如果很倾斜的看我的Texture,我就预先Filter到最远处的Mip去了,效果就没有了
- 这一种平时注意不到,实际上在场景中很多高频的(高频:幅度很小但是变化速度非常快),比如高光,移动一个物体的时候他上面的高光流动非常迅速,他也是游戏中产生Alising很重要的一个原因
-
最基础的方法,SSAA
超采样,以牺牲巨额的性能来代价,让一个点多采样一些点,基本不用。 -
MSAA
虽然还是多倍采样,但会对比是否落在一个采样点,只做shading一次,如果有多个采样点落中,则用权重均衡。
这种方式,现代硬件很早就支持。 但仍然需要四倍ZBuffer。方法虽然好,但是在现代游戏中的几何密度是非常高的,比如UE5最新的Nanite技术,三角形数量可能大于像素数量,MSAA就会彻底失效 -
FXAA
Fast Approximate
其实在边缘处会产生颜色的跳变,在计算机视觉中有一个叫做“Edge Detection”,将图片中的Edge提取出来,在Edge地方采用插值的方法,就能产生反走样的效果。首先使用十字形滤波,把每个像素点的相邻数据计算差异值,当平均差异值大于某个阈值的时候,那么这个点就是一个边界,这个阈值具体是多少,是把整个空间,转换到一个亮度空间,亮度空间是有颜色的,每个颜色对亮度有一个色感,如上图右侧显示,绿色贡献度最大,蓝色贡献度最小(这都是经验数值,手机中把彩色照片变黑色照片使用的就是这个数值),变成黑白照片之后,对其上下左右相邻的进行寻找比较色差,如果色差超过这个阈值的时候,说明这个点就是边界点,就有可能需要AA了
取边界的方向:
以下图为例子,取了很小的一块区域,纵向、横向做了一个卷积,最后求出横向的差异度更大一点,再去判断是左边的差异度大,还是右边的差异度大,就会得到一个Offset朝向,如果我要进行AA反走样的Blending的话,应该和右边的Blending,因为他们之间的差距大,大概率就是这个地方会出走样的问题
速度快,大部分都直接集成在显卡里
- TAA
它的核心思想是,由于在游戏世界,对过去渲染了很多帧,只要在过去的帧数中找到像素对应的时候,把信号拿过来进行加权平均的时候,实际上也是完成了信息的Blending,现代游戏引擎很多时候用到了【Temporal 时续】上的数据,这一帧,会利用前一帧的数据进行计算,这其中引入了MotionVector,当前像素看到的每一个点,它在上一帧会自己动,相机也会动,就会去寻找关系,该像素在上一帧的位置,如果动了的话,它的Vector就会往这个方向走一走(这其中很复杂,需要在渲染中进行准备),有了这个之后就可以和上一帧进行Blending,TAA也不需要你做更多的采样,在时间轴上找数据,也是能够进行AA的运算
其中有一个细节,当在告诉运动的时候,我们更加相信的是当前这一帧运动的结果,如果是静止的话,两边的权重是差不多的,所以对于运动的物体,当前帧的权重会略高一点。所以TAA目前也是AA主流的算法
TAA关闭和打开时候,有一个小小的错位(下图标记处),因为相机一直在动,而TAA老是在和过去的图像进行Blending,所以有一点点小的Offset,这是讲师个人认为的一些问题,而且TAA做不好的时候会出现一些残影,这也是时序上比较的时候出现的问题
7.4 后处理
后处理无非两个目的
物理上把它做正确,比如让画面“正确的”被曝光,比如相机拍照,整个真实世界光强的明暗变化幅度是很大的,太阳光可能是烛光的几亿倍,但是拍成照片的时候,只有正确的曝光才能产生效果;比如还有一些光晕的效果,这些都是物理真实的需要
风格化的表达,比如Color Grading的效果
- Blooming 光晕
Bloom在计算中有一些讨论,关于为什么人眼看到强光后,可以看到周围的光晕。一种解释是人眼和相机一样,相机有一个光圈,对于凸透性的成像,因为它并不是一个完美的小孔成像,实际上它无法完美的聚焦到一个焦平面上,所以就会造成一些发散,发散之后有一个叫做Airy Disk,会看到这样一个Disk(如下图);还有一种解释是人眼中的睛状体里是【半透明/有介质的材质】,这种类似气溶胶,光照射之后会产生一个有极向的散射,当光射入眼睛里的时候,眼睛里有很多小叶珠,会产生一些散射,这些散射在视网膜上产生了散射的效果(不管是什么原理,这个效果我们是真实可见的),包括有一些照片,也能产生Bloom的效果
做法:
- 首先将其光亮地方取出来,将整个画面转成Lumenence、转成它的亮度,即之前讲的亮度算法,三个颜色给个不同的权重,绿色权重最高,蓝色最低,当它的亮度超过某个阈值的时候,这个阈值有时候就设置为1,但是这个数值等于1在现代游戏渲染中也不一定正确,因为现代游戏基本都是HDR的,光强幅度很大,所以有时候会以平均光场亮度来计算会更好一点。取出来的记住是它的颜色,不仅仅是它的强度部分
- 然后对其进行Blur一下,这里使用高斯模糊,实现高斯模糊假设我做一个5x5的卷积的话,可以通过2次5个像素的卷积,就可以实现25个卷积。你可以理解成对于每个点,第一个Pass把他上下的2个相邻像素合到一起去形成一个结果,第二个Pass,还有每个点,将上一个Pass的结果左右合到一起,这样的结果就相当于把周围25个像素全部取了一遍。比如说我的高斯Kernel卷积很大以9为直径,原本我要卷81个数值,现在只要卷19个,这样的计算量就会小很多
减少计算复杂度的办法:
使用Pyramid思想
加上高斯模糊后就可以得到Bloom的“圈”,但是这样Blur的区域其实不够大,要形成理想效果的话Kernel可能需要30~40个,那即使使用上面的方法,每一个像素点,也要卷上百个数据非常不合理,我们就使用了一个非常经典的【Pyramid】的方法,对图像不断进行DownSampling,在最低阶的Kernel进行Blur的话,对这个效果经过一级级的放大回来,光晕就会很大
所以做法就是在最低的一阶进行高斯模糊,然后把它放大之后和原来的图“加”到一起,不过注意这里的“加”是有一定权重分配的,每一层加回来之后,再对它进行一次Blur,再把它放大,再把它和上一级加权合到一起、再放大,最后就可以得到上图光晕被合的很开的效果,但是计算量远远小于在最高精度图上,进行一个大的放大。这个思想在处理Half Resolution、MipMap,从低往上算,都是降低计算复杂度的方法,最后便形成了Bloom效果
- Toom Mapping 曝光
曝光如果没有仔细调过的话,要么亮部过亮,要么就是暗部过暗
ToneMapping基本解决的问题就是,基本目前游戏渲染都是HDR的渲染,即阳光直射到的地方亮度会非常非常高,但是阴影中亮度是非常的低,如果不通过曝光曲线,把这么大的光照数据,映射到一个LDR/SDR(Standard Dynamic Range)映射数据的话,如下左图,天空已过曝了,实际房屋出现了色偏、看不清的情况,因为颜色很高超过1的做Clamp截断的话,HDR的颜色会产生一个色偏的,下图用了一个Filmic Curve来调整,这个算法本质很简单,将0~40的值,通过一条曲线,映射回一个0-1之间的值。这个映射在二维空间上就是一条曲线
曲线:
- Filmic s-curver Tone Mapping
ToneMapping实际上有很多曲线,但是行业发展后,经典曲线就几条,先说最著名的Filmic s-curver Tone Mapping(好像是顽皮狗先提出的),这样一条曲线,我在游戏中取出任意一个点的Lumenence强度,去计算新的映射的时候,如果做成纹理来进行采样的话效果很低,这里他们是使用一段多项式的拟合,拟合成这样一个ToneMapping - ACES
不过现代行业中慢慢流行起来的是ACES,效果很不错是由电影级的大师们制作的曲线,主要解决了我们渲染出来的结果,实际上会在不同的设备上播放,比如说显示器是否是HDR还是普通显示器,还有一点是人眼对颜色的感知是相对的,比如你在一堵白色墙壁中看一张绿色的纸,和在电影院中看一张绿色的纸的画面,实际上如果要让观众看到同样的颜色效果,实际上是需要调整的。而ACES的Tone Mapping给你转换完成之后,后面加一道工序的话,就可以无差别的适应到各种影视终端。它们的所有的数值,所有的曲线,都是由大量的专业的视觉艺术家去调效果的(在Messiah中类似的推导在EngineShaders/Include/ACES.fxh头文件中,相关项目组同学可以自行查看)
- Color Grading 调色
刚才讲的Tone Mapping和Bloom还是比较真实世界的东西,Color Grading就是美颜而已,现代游戏中去表达情绪会通过Color Grading来调整,其中有一个LUT:Lookup Table,本质就是原始颜色,和我想调到的色相空间的映射,这个映射用一个表格来做
LUT其实不用太复杂,世界上所有的颜色,本质就是一张3D的Texture,任何一种颜色,变化为另一种颜色,其实就是映射。由于早期很多硬件不支持3DTexture,会把它拍平成一张2D Texture,一样是可以存到Shader里面,这其中有一个小细节,其实我们并不需要存一个(256,256,256)大的Texture,实际上工业界使用16x16或者32x32
7.5 Render Pipeline
可以理解为绘制顺序,实际上那么多套算法它必须有一套规则,谁先做谁后做,才能保证这个是有序的,【游戏引擎中的算法】,和【图形学中的算法】最本质的区别在于,我们无法抽取出一个简单“干净”的算法,实际上一个画面中几十种甚至上百种算法同时在运作,然后要保证效果不出问题,这里面就需要有一个Pipeline,将这些算法依次往里面放置
- Forward
最简单的Pipeline就是先将ShadowMap计算出来、光影明暗计算出来之后,把物体依次放进去对它进行光照、Shading,最后将最后的结果,放到Post Process里,比如Bloom效果计算,进行一个曝光,一个Color Grading,就能拿到我想要的结果,这个就是一个最简单的Pipeline,即Forward
对每一个Mesh、每一个光进行渲一遍,天空之所以在最后绘制,一来是因为其最远,二来是因为Forward Rendering有一个小细节就是,我们有一些物体是透明物,透明物的绘制
注意一点:首先不能和不透明物体混合在一起去计算,必须是最后去绘制,而且它还有一个Transparent Sorting 透明物排序,也就是说当我在屏幕上叠加透明效果的时候,如果你的不透明材质在前面的话,就会挡住不透明物体,也就不需要绘制了,Z-Buffer我就知道了;但是如果位置互换的话,我实际上是要混合不透明物体的部分颜色,实际上不透明的计算那就必须在其之后再计算,这是透明物和不透明物体之间的关系
那如果有更多透明物体的情况下又应该如何处理呢?这其中就涉及到了Transparent Sorting,把所有的透明物由远及近的绘制,在现代游戏引擎中,这是一个很困难的问题,会导致很多Bug,比如一些特殊形状的模型,还是会存在一些物体,有时候用透明物的中心点来排序;还比如你打CS丢出去一个手雷,这个手雷引发的烟雾的排序,就非常困难解决
- Deferred
Deferred的思想就是在第一个Pass中,优先把所有的物体渲染一遍,但是先不去进行计算它和光的关系,光的计算放在后面,先去计算例如Albedo、Roughnes、Depth全部存到一个巨大的G-Buffer中去;当我有了这些信息之后,当光Apply到屏幕上信息的时候,就可以只计算光的部分了,这样所有的像素就不会被Overdraw,即最后的Shading运算,只会计算最后一次,所以Deferred Rendering在过去十几年中最常用的绘制方式
还有一个潜在的好处是,我们材质使用PBR统一之后,早在PBR流行之前,人们也已经习惯把材质数据,全部拍到我们的G-Buffer中,让后面的计算高度的一致,这样就可以绘制很多光源的结果
Deferred管线的好处在于对光的处理,渲染也很容易Debug,缺点是G-Buffer是非常的费的,在硬件上实际上读写这些数据的效率是非常低的
- Tile-based Rendering
Tile-based的源头在移动端,但是移动端有一个问题是他对发热是特别敏感的,在移动端最容易发热的就是存储芯片。所以它做了一个结构,在主板上有一个DRAM,他速度比较慢而且读写比较消耗能量,但是它在Chips中又做了一个SRAM,SRAM频率特别高但是尺寸特别的小,这时候就在Driver层面,将屏幕画面切成一小块一小块的,就一小块的只渲染这一小块的几何内容,渲染好之后将结果放到Frame Buffer中去,而不需要去存储一个巨大无比的G-Buffer。
这样切分还有一个好处是,光可以被Culling切分到不同的Tile中,即屏幕中的小Tile,实际上用户是知道是被几个光给照射到的,每个Tile只要做一个很简单的View Frustum的处理,我就知道这个Tile中有几个光可见,这叫做Light List
再往后走一步,实际上在渲染世界的时候,在做Shading的时候,会生成一个PreZ,会生成一个Z-Buffer的深度,实际上在每个Tile我是可以知道最远的和最近的Z在哪里,右图我们以摩托车为例,它的BackFace是不会被Shading的,只有FrontFace形成了一个个小的区域,假设有一个点光源,点光源在空间中一般是球,我们就知道哪几个Tile会被它照射到,哪些空间有但是不会被照到,可以看到下图实际上被照射到的只有几个点,很多Tile不受到影响,这就是对空间划分后带来的优势
-
Forward+
如果是Forward管线Rendering,但是是按照一个个Tile去绘制的话,就叫做Forward+,这个对移动端会特别友好,即使在PC端也会有人来做 -
Cluster-based Rendering
其实在像素空间中进行切分的时候,刚才在Z那里我们是做了Zmin和Zmax,实际上还有一个更简单的方法是我们直接对Z空间直接进行一个切分,把空间分成那种四棱锥的体柱,这种Cluster-based Rendering就可以处理上千个光源,非常高效,现在Cluster-based Rendering也在慢慢变成很多游戏引擎中用的方法,但是这个方法个人觉得没什么花头,实际上就是不用计算Zmin和Zmax,而是对应一个一个去算,对于Light的Visibility -
Visibility Buffer
最后介绍一个目前蓬勃发展的一个Rendering Pipeline技术:Visibility Buffer。上面介绍的所有的渲染,大部分是使用的Deferred Rendering,本质上是把所有的材质信息,写到了一个巨大的G-Buffer中去了。但是随着现代硬件的发展,我们其实可以把【几何信息】,与【材质信息】剥离开来,我在一个Frame-Buffer中写这个像素是属于哪个几何体 Primitive ID、Triangle ID信息,还能通过三角形的重心坐标,就可以反向去查找到这个三角形用的是什么材质,所以使用一个Visibility Buffer就可以将几何信息全部存下来了,有了这个信息之后我们就可以直接的对它进行Shading
这个之所以重要是因为我们过去一直认为材质渲染比较复杂,而几何比较简单,包括上图的UE Nanite技术,《地平线》中Foliage,几何密度是会非常高的,几何会超过像素,传统的去写G-Buffer方法的话,其实会浪费掉大量的几何的Overdraw,然后要去大量的Texturing大量的运算
所以这时候当我们发现,我们只需要把几何写进去就可以了,那么这个在现代游戏引擎中,逐渐称为Rendering发展方向,而且现在Geometry Shader、Mesh Shader越来越成熟之后,走传统的Vertex Index Buffer传进去,把它变成光栅化,再进行Pixel Shading,它的效率其实没有我们自己去写光栅化的效率高,自己用GPU去写Shader Code,把三角形光栅化成一个点,比硬件做的更快。还有一点是在做Pixel Shading的时候我需要不停的去查G-Buffer,那个Texture Sampling效率是非常低的。但是我在Visibility Buffer做Shading的时候,实际上是直接去查找【VB】和【IB】,那个效率实际上是非常高的,所以Visibility Buffer是现代Pipeline一个很前言的发展方向,预测之后会有越来越多的管线会引入这个机制,但是目前而言这个Visibility Buffer并不像Deferred,像一个主干的Pipeline,未来说不定因为技术成熟会成为主干
通过几何的全属性反向的找到材质,而且它用了Visibility Buffer还有一个好处是说,我把所有没有用的材质信息全部给剔除掉了,只需要用我自己需要的材质,而且它能支持的材质类型更加的复杂丰富,相反如果使用G-Buffer的话,假设材质可能都是一致的
- 挑战:
做完一个引擎,提供各种游戏的时候,会遇到以下困难
- 有的游戏需要的是TAA,有的使用的是FXAA更注重效率,但是又有那么多的模块,这些模块有点类似积木,这些积木如何自由的搭建
- 第二点是每一个算法,除了计算之外,还要占用很多存储资源,这些Buffer实际上在整个一帧渲染里面,并不需要从头到尾,可能只需要一个计算,计算完成之后把结果传递给下一个计算后,这个计算就应该被释放掉,如果你不对它进行一个精密的管理的话,你会发现很多内存空间、显存空间全部是被浪费掉的,当一个Pipeline变得复杂的时候,几乎没有人管理的了这个事
- 随着DX12和Vulkan Graphics API的兴起,这一代的API最大的设计理念是不再像早期的OpenGL、DX9、DX11一样,把很多硬件的复杂度给封装起来,在Vulkan或者DX12中,几乎是将裸的硬件的算力给开放了出来,包括内存怎么去管理,如何去理解这个内存、这个内存是一个Texture还是一个Array、这个内存是可读还是可写、我是否应该将这个内存屏蔽起来,由于我们的GPU是一个高度并行化的计算,很多的内存是要加锁的(Memory Barrier),这个锁一旦没有加对,或者少加的话,要么导致整个游戏直接Crash,要么死循环、即死锁
其实这些在现代游戏引擎中困难时非常大的,如何解决就需要我们使用Frame/Render Graph
-
Frame Graph
无论是Unity还是UE,他们的SRP(Scriptable Render Pipeline)其实就是这个概念,我们将Pipeline中的所有东西,变成一个个Modular,这个Modular可以用脚本,甚至可以用可拖拽的图,把这里面的Pipeline,里面的计算,它的资源的依赖,依次用这个有向无环图(Directed Acyclic Graph)把它表达出来,然后系统自动帮你去检查,他们彼此之间的依赖关系,自动帮你优化这些资源之间的可重用的部分。比如说我发现一个Buffer,之后的运算实际上是用不到的,那就将其释放掉,然后再另一个计算中再用上,这叫做Aliasing,将这个Buffer给Aliasing过去,这样一个东西,就能够避免很多同学犯的错误 -
V-sync
本质原因是因为我们的引擎在疯狂的渲染,但是引擎的每一帧时间是不一定的,有的场景复杂,有的场景简单,它的帧数有的时候是不一定的,但是显示器刷新的频率是一致的,那么如果这个时候凑巧错过了它的刷新频率的话,就会出现在等的情况,这个就是Screen Tearing产生的原因,所谓的V-Sync非常的简单,每次必须把FrameBuffer写完之后,等到下次刷新的时候,整个Frame刷新过去,而不能是写到一半刷新它
Variable Refresh Rate,就是将显示器的刷新频率,变成动态可调的,游戏按照什么帧率去渲染,我就对接在一起,就不会有这些问题。在V-Sync时可能出现的问题就是,因为一直在等显示器的刷新频率,就会导致画面一会快、一会慢的情况发生,因为正好错过了一点,这个对于眼尖的玩家是会发现的(不过这个对现在来说还好啦,毕竟显示器的刷新频率越来越高了,但是这并不妨碍去解决这个问题)
这就是写游戏引擎渲染的最后一步,要把渲染的内容,投到屏幕上去
8 动画
8.1 动画技术
-
Dof(自由度)
Degree of Freedom (DoF)定义了一个游戏物体拥有的自由度,即:系统的自变量或参数的数量。简单来说,就是游戏物体由多少个维度可以发生变换。
所谓6Dof :
对于刚体而言,在整个三维空间运动的自由度便是六个,包括:平移(沿着 X 、 Y 、 Z 轴平移)、旋转(绕着 X 、 Y 、 Z 轴旋转),也就是三个平移 + 三个旋转。一个支持 6 DoF 的虚拟现实的眼镜,即可以支持用户可以以以上这六种方式观察 VR 场景。 -
Per-vertex Animation
当动画使用mesh较难处理时,将顶点动画。 现在的3A游戏都会采用此技术 。 -
Morph Target Animation
主要处理面部动画相关,在Per-vertex Animation添加骨骼差值
变形目标动画是一种顶点影响权重的动画,是使用 LERP 在每一个关键帧之间进行插值,主要的应用是制作角色的表情动画,如:捏脸系统。Morph Target 可以解决当变形过大导致的效果不自然的情况,因为这种方式是在关键帧之间进行插值计算。
存的是顶点的位置,更像是顶点动画。
缺点是数据量非常大 -
3D Skinned Animation
mesh与关节相联,最常见的动画模型。
蒙皮动画的核心思想便是:网格(或蒙皮)绑定到骨架的关节,蒙皮的每一个顶点的运动不止受到一根骨骼的影响,而是多根骨骼的运动加权影响。即可以保证当角色在运动的时候,是水密性的。相比于早期的刚体动画更加自然。 -
2D蒙皮动画
技术原理与3D类似 -
基于物理的动画
基于物理的动画是一种比较复杂的动画技术,在游戏引擎中主要的应用是 Ragdoll 布娃娃系统,用的最多是在衣料的模拟。 如:角色受到撞击或者死亡时,会触发 Ragdoll 效果。另一个基于物理的动画的主要应用是布料模拟,如:角色在运动的过程中,衣服会跟随飘动。以及后续会涉及到的 IK (反向动力学),即如果根据指定点,角色如何运动会更加自然。 -
动画内容生成
动捕,或是由美术同学K动画
IK相关: 如何给定一个点,如何表现这个动画才更为真实。
8.2 蒙皮动画实现
- How to Animate a Mesh
给定一个角色的模型(Mesh),让这个模型动起来需要以下五个步骤:
制作模型的 binding pose;
为这个模型制作 binding 骨骼,骨骼可以和这个模型的 binding pose 对齐;
使用笔刷工具为 Mesh 的每个顶点刷上权重,即:受到不同骨骼影响的权重;
驱动骨骼到需要的位置;
通过骨架和蒙皮权重为蒙皮顶点设置动画。
- 骨骼的分类:
一般需要一Pelvis中轴,还需要一个Root,但这样分类仍然只是一个最基础版的标准骨骼,实际游戏开发中可能会加更多的骨骼。
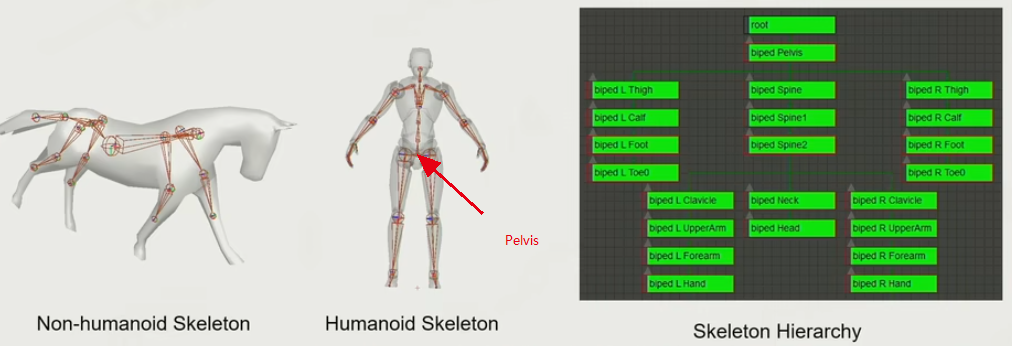
标准骨骼并没有一个绝对标准,视项目组中的TA与决策人员一起讨论决定。
-
Joint vs. Bone
需要进行区分的是:Skeleton 是骨架, 而在游戏引擎中表达的则是 Joint—关节,即一些肘关节的数据。Joint 是动画师直接操纵以控制运动的对象,Bone 是关节之间的空隙。因此,当肘关节发生旋转或者平移的变化时,会连同 Bones 带动其子 Joint 进行运动。最主要的区分便是 Joint 和 Bones 的自由度不同,Joint 不会发生 Twist 的变换,而 Bones 可以。 -
骨骼规范
Root 的位置及Pelvis的位置
如一种 Root 是针对四足生物,以马匹为例:马的 Pelvis 一般会放置于尾椎,而 Root 则放置于马肚子下方,这样据可以很方便的表示马的位置.
-
骨骼Bind
两个skeleton绑定在一个骨骼点,与Gameplay密切相关。 -
A-Pose,T-Pose
原本多数使用T-Pose,但由于肩部挤压的问题,现代更多的使用A-Pose -
Skeleton Pose- 9 Dof
在6 Dof基础上加上放缩, Scale维度
8.3 数学
-
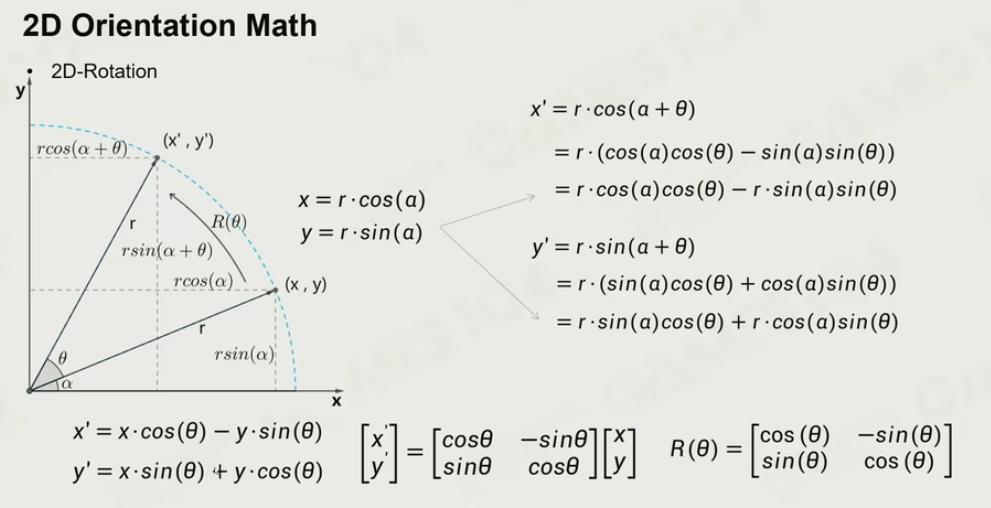
二维空间的旋转:
-
三维空间的旋转

-
Euler Angle
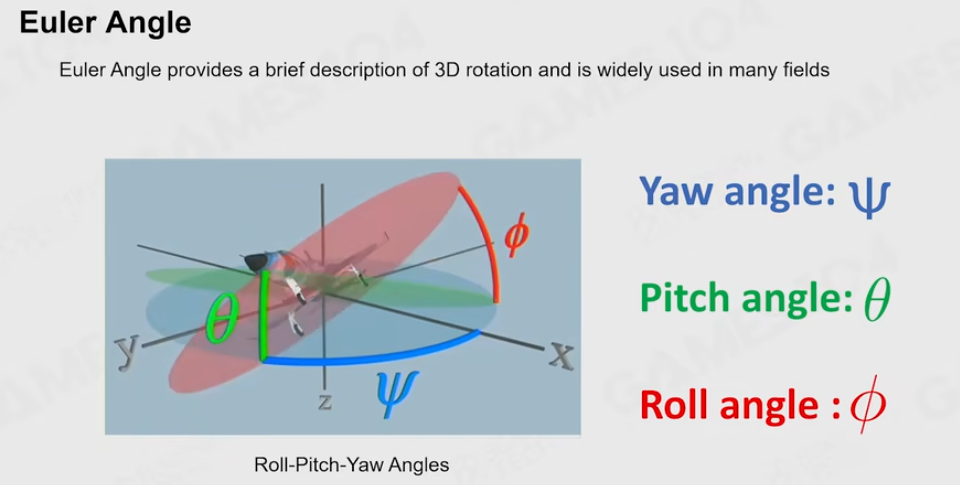
欧拉角在实践中有一种很广泛的应用——万向节
问题:
严格的顺序依赖
-
万向节锁由于自由度的丢失,会导致整个模型的旋转被锁死,如果有两个空间的旋转,从旋转1到旋转2进行插值的时候,便会出现问题。欧拉角除了万向节锁的问题之外,还有一些其他的问题,如:难以插值奇点问题使插值变得困难,旋转组合需要旋转矩阵,易于通过 x、y、z 轴旋转,但对绕任意轴的旋转来说比较困难。
-
难以插值:给定旋转值 \alpha_1、α 、\beta_1、、\gamma_1$ 和 \alpha_2、α 、\beta_3、、\gamma_3$,这两个旋转值之间不能用简单的线性插值方式。
简单来说就是:单个欧拉角能够正确表示旋转无论死锁还是不死锁,但是当两个欧拉角插值的时候,由于死锁的存在,导致插值后的欧拉角表示的旋转与原始的两个欧拉角表示的旋转差异很大;一种旋转可以用多种欧拉角表示,例如,x 角度为100,与 x 角度为460其实是一样的,x 角度为-179其实和+179很接近;当欧拉角接近死锁的时候会引起抖动,例如:48.5557 82.8384 48.0888以及 141.922 81.0177 142.027,这两个欧拉角其实非常相近,但是除了 y 角之外其余两个坐标差异比较大。因为两个欧拉角的 y 旋转角度都接近 90° 了,越靠近 90°,y 轴的微小变动就对 x、z 两个角度影响非常大,所以进行插值的时候直接进行插值会引起抖动,上面的插值结果可能为 5.23894 90.9103 5.05811,这个结果与上面两个原始角度所表达的方向都不一样。 -
如果要使用欧拉角进行插值的话,将需要插值的两个欧拉角转化成矩阵,再通过矩阵分解出所有可能的欧拉角,找出两个比较相近的欧拉角进行插值。
-
旋转组合困难:例如角色的动画,关节 1 做完了一个旋转,其子关节再进行一次旋转的情况,这种情况下不能简单地将两个角度相加进行计算
难以按某个轴旋转:欧拉角的旋转表达大多都是沿着 x、y、z 轴旋转,如果要计算绕任意轴旋转的话,欧拉角的表示会变得十分困难。因此,一般在编辑器中为了方便美术更加直观地操作,会使用欧拉角的旋转方式。 -
四元数

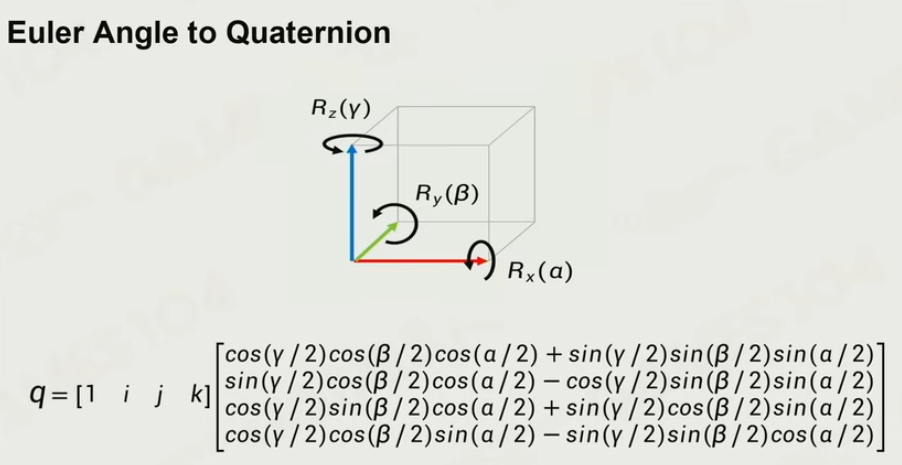


8.4 Joint
动画系统的差值,采用的是LOCAL SPACE
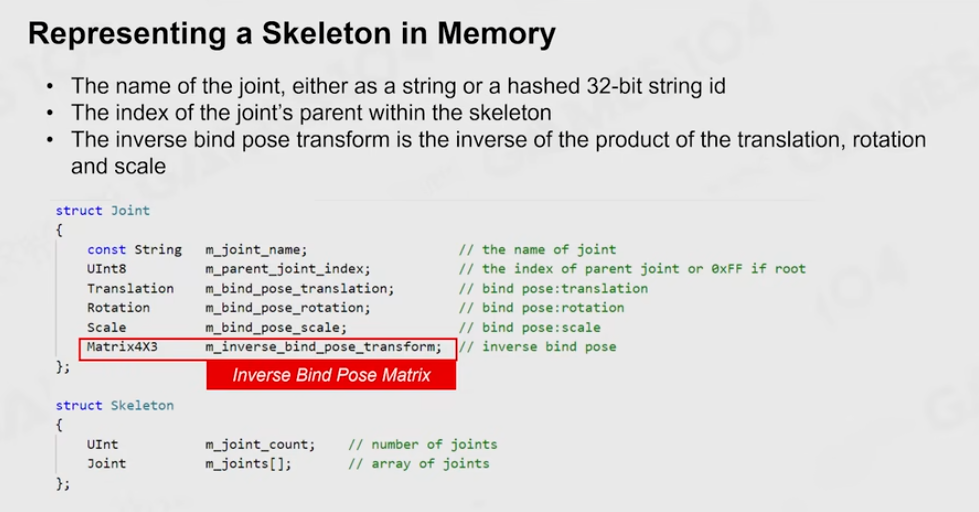
- Skinning Matrix
顶点绑定的一个位置乘上绑定父关节的仿射矩阵的逆,得到一个相对位置。再把这个相对位置乘上变化,就可以到新的模型空间的值。这个值的新的坐标值,注意要乘上绑定的仿射矩阵的逆。

在做动画的时候,一般在每一根骨骼都存上Skinning Matrix。给你模型上任一一个点,就得找到这个绑定骨骼的Skinning Matrix.
最终还会转到世界坐标系:

所有的推理的原理就是一个恒等式: 每一个根节点相对于父的结点的相对位置是一定不变的。
-
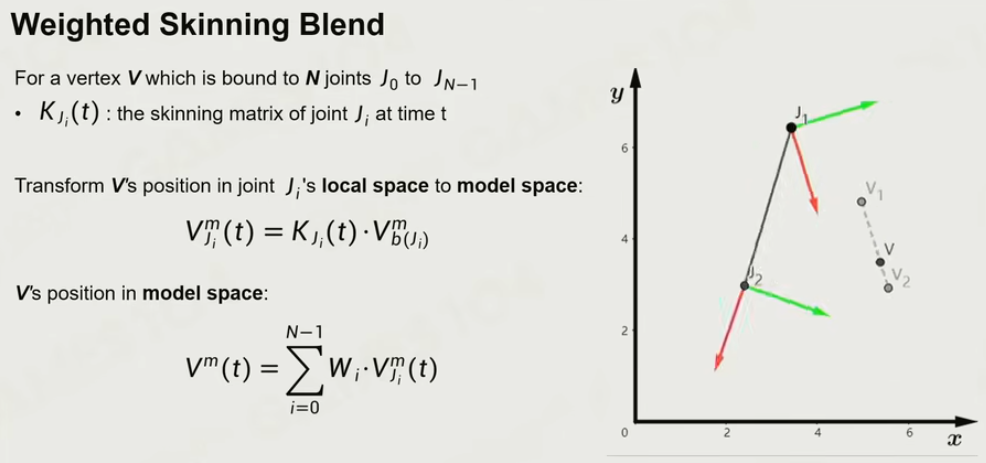
蒙皮动画
一个顶点与多个关节起作用,原理就是加权平均的做法。
注意一定要在model space做
-
多个Clip之间的差值
位移:线性插值
旋转:LERP与NLERP,对于四元数进行线性插值,NLERP对此结果进行归一化。
NLERP的最短路径问题

- SLERP
找出夹角值,对于此角度值进行插值。 对于角度值很小时,差值就会很不稳定。

对于NLERP/SLERP来说,判定角度大小来使用哪一个。
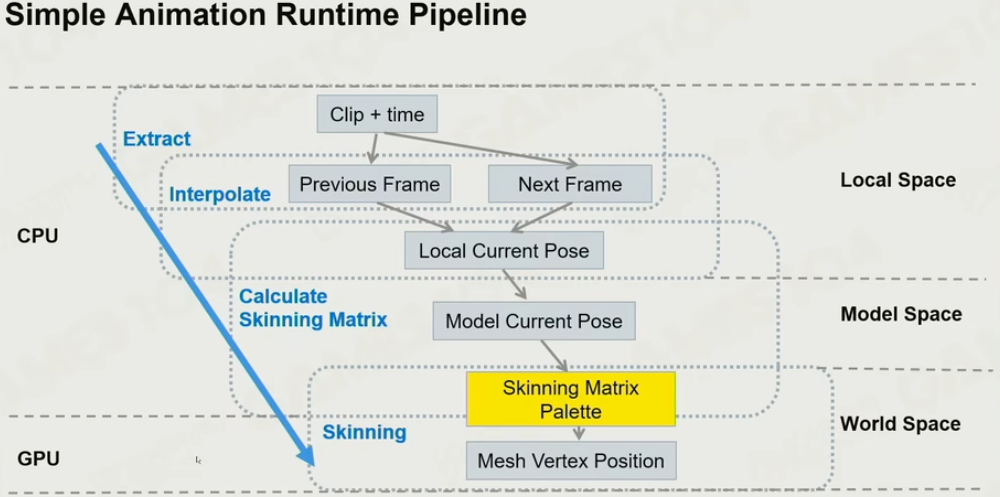
- 动画管线
8.5 动画数据压缩
-
DoF Reduction
首先去掉不变的数据。
对于Rotation: 使用Keyframe的方式去插值,关键帧之间的间距是不相等的,取决于信号 -
Catmull-Rom Spline
由于旋转的线性差值影响实际的效果,这里定义一个多项式的曲线,实际上是非常光滑的曲线,这样做出来的差值,使用的数据就会少很多。

-
Float Quatization
将数值定点化到一个范围。
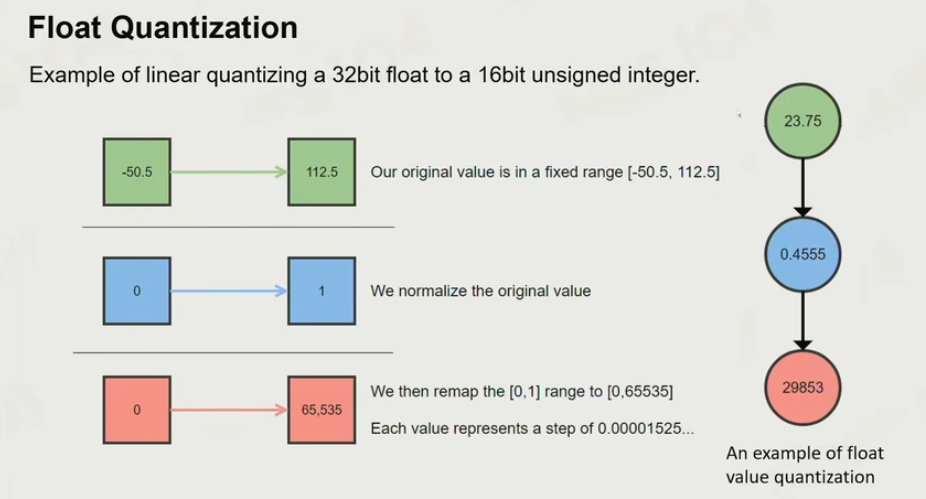
四元数的浮点数定点化压缩:
把最大的数拿掉,把剩下的三个数拿下去,就可以反向算出


把16个bytes*8 = 128bits,压缩到了48bits.

- 动画压缩的问题
Error会被一层一层放大到子关节
不同的骨骼对于Error的敏感度是不一样的
行业上需要注意Visual Error:
解决办法:
- 在joint定义两个垂直的点,给出一定的offset,如果敏感点,则offset给小点,如一些小骨骼。
- 进行误差补偿
8.6 动画制作 Animation DCC Process
Animation Digital Content Creation Process
- 使用低精度MESH做动画
- 快速创建骨骼和skinning
- 制作动画的关键帧
ROOT一般只导出为位移曲线,并不放到动画里
顶点绑定的关节一般为4个(手游可能更少,2个),实际上是没有限制
9. 高级动画技术
9.1 动画Blend
区别于CLIP内的差值,Blend表示在不同的CLIP之间的差值
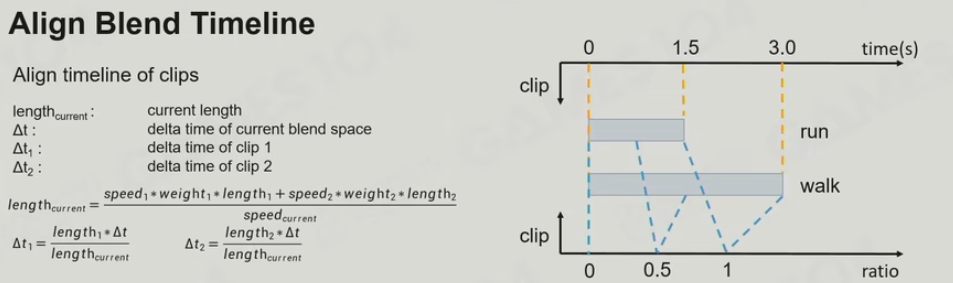
- Blend Weight:差值的权重
- Align Blend Timeline(UE SyncGroup): 将两个循环动画的时间归一化,不同的clip之间的时长不一样。
9.2 Blend Space
- 线性Blending
1D Blend Space: 1维
玩家由不同方向移动。
在不同的角度的之间对三个clip进行混合。
不规定clip总数,也不要求clip在轴上均匀分布
2D Blend Space
Directional Walking and Running
2维:同一时间改变方向和速度
这里要求动画都必须是循环的

根据顶点生成空间三角形划分,对于任一个点,找出邻近的三个点进行插值
-
Skeleton Masked Blending
对于上下半身或不同骨骼的动画混合,将骨骼进行Mask进行混合 -
Additive Blending
只存动画的变化量,而不是绝对量,无论skeleton怎么变,都可以加上这个变化量。
可能导致Joint的动画异常
9.3 ASM
-
动画状态机
对于不同动画行为之间的控制,需要状态机,从状态A以一定条件到状态B
NODE - TRANSITION - NODE
完整的ASM的Transition条件可能多于一个 -
Cross Fades
Smooth transition
Frozen transition
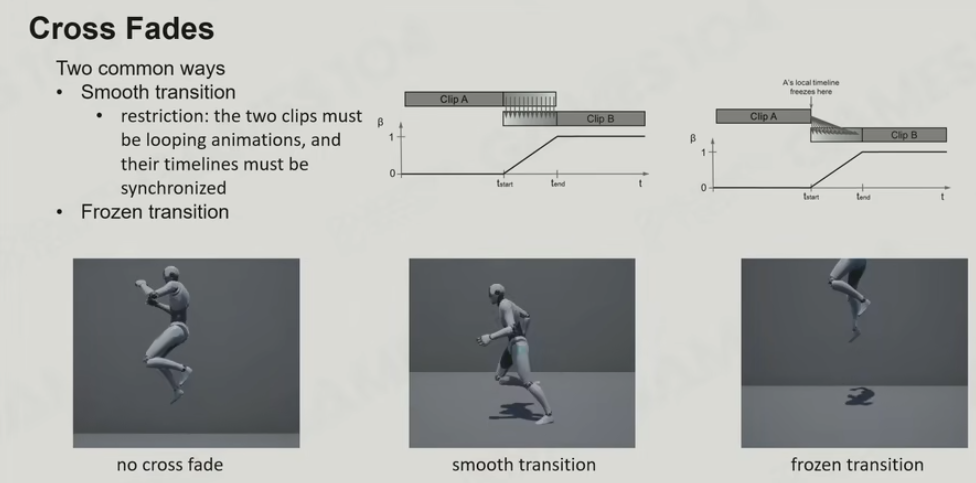
引入Cross Fades Curve针对不同的变化方法选择曲线,如Linear, Sin in/Sin out … -
Layered ASM
不同部位的身体实现不同的,独立的行为控制
9.4 Animation Blend Tree
-
LERP Blend Node: 线性差值的权重
-
Additive Blend Node
更好的表达Layered ASM
更自由的Node表达,甚至是一个递归结构

-
控制变量: 定义更多的变量提供给外面的系统
9.5 IK
-
基础概念:
End Effector: 末端效果器,一个骨骼能被期待移到某一个点
IK: The use of kinematic equations - 先约束好,就是需要End-effector移到一个点。
FK: The use of kinematic equations - 驱动关节,从根到上,往前传递的动力学 -
Two bones IK:
由简单的两个球求交,算出角度。
但在一个球面上,角度是不一定的,因此需要额外一个Reference vector。 -
复杂的情况
当多个Joint涉及到IK,即长链式的IK,则变得复杂 -
如何做
算出目标点是不是能够到,有哪些骨骼能够到?
- 把骨骼拉直,长度够就够?
- 把最长的骨骼放好,把两端所有的骨骼对折,如果无论怎么折都没有办法覆盖,但会有盲区,导致永远找不到
- 使用Heuristics Algorithm
算法1: CCD - Cyclic Coordinate Decent
一步步从end-effector往目标点方向旋转,不断循环这个过程(真实一般情况也会有十几次也正常)
优化1: 翻的太猛了,做一个tolerance region,这个范围限定每次翻转的上限
优化2: 越靠近根结点旋转越小,越靠近叶子结点旋转越大
With Constraints:
骨骼每次动不能超过约束
算法2: FABR-IK Forward and Backward
FORWARD: 先从头节点往前往目标点移,一直移到最后
BACKWARD:由于FORWARD移动了尾部节点,这时把尾部节点往原来的点移,一直移到头节点
以上两个步骤不断循环。
优化: 与CCD类似,也需要设置一个Error tolerance范围。
With Constraints:
对于有约束的骨骼只在限定的范围用
- 多控制点(End-Effector)的IK
因为共同结节的变化,其他点对他的变化会导致变动
Jacobian Matrix:
当长链条每个轴的旋转导致的端点的变化,把角度相像为向量X,端点在空间的位置为关于向量X的方程。
对于这样的方程组,可以用梯度,导数矩阵来转换
不断的一小步一小步的执行Jacobian Matrix,再向上继续执行
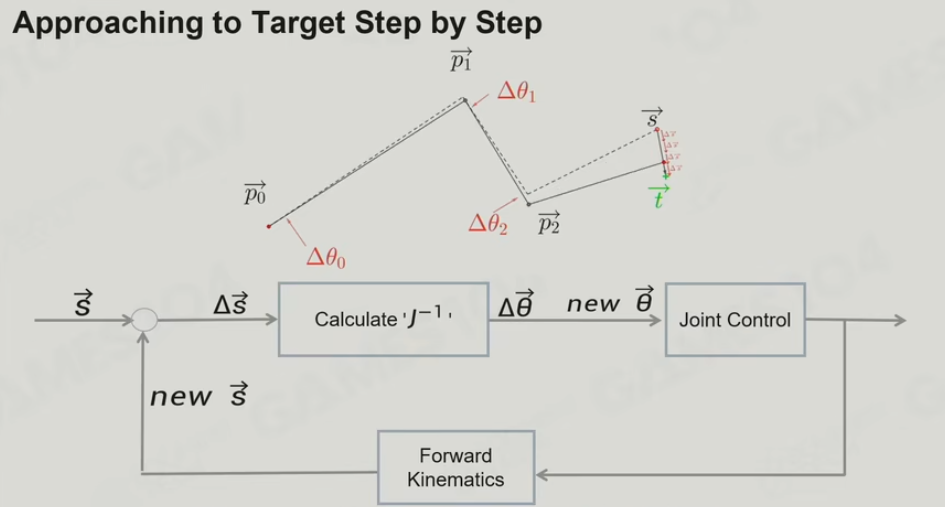
非常耗时
- 挑战
- 自我collision的处理
- 移动过程中的如何做预测动作
- 更自然的人类行为学
9.6 Facial Action
-
基本了解
人类44个面部肌肉 -
Facial Action Coding System
归纳人类的表情为46个分类 -
Apple Inc. 归纳为28个核心Action Units

-
把28个核心AU做成各个Key Poses
问题:如果存的是每个顶点在表情下的位置,这样blend可能不是想要的结果
在blend时只针对每个表情需要只某个AU的部分去做。 -
使用Morph Target Animation
但也会结合Skinned骨骼 Animation, 比如眼球 -
使用UV Texture Facial Animation
常用于卡通渲染 -
前沿: Muscle Model Animation
Unreal的Metahuman
9.7 Animation Retargeting
在不同的角色共享一套动画
- Source Charactor
- Target Charactor
- Source Animation
- Target Animation
处理offset的情况,注意需要存储相对于关节点的相对offset
Retarget的方式:
Omniverse
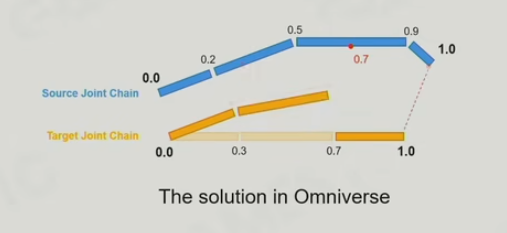
问题:
- retarget后的自穿插问题
- 角色上的动作限制
- 平衡感
Facial Action的Morph Target Animation也会有retargeting
10. 物理基础
10.1 理论
物理一般放在Logic部分,但也不是绝对的,如用物理做粒子效果之类的。
- 物理处理的对象(Actor)
- 静态Actor,档板,曲面等,移动会被受制于,量一般是最大
- 动态Actor,动力学
- Trigger, 类似于静态Actor, 不移动,也不阻档,当actor进入离开时通知
- Kinematic,No Physics Law。 根据游戏的需要,把actor动来动去,本身来说是反物理,由游戏逻辑去控制。
-
对象形状
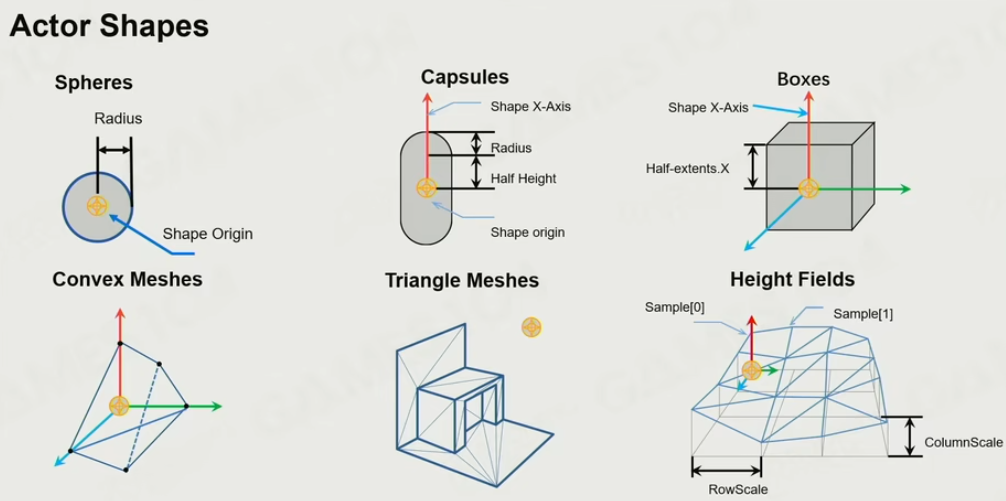
球:对应球类的游戏中的球
胶囊体:表达人形物体
Box: 建筑物,地形部件
Convex Meshes: 对于复杂的形体,破碎的碎片
Triangle Meshes: 密闭的,一般只允许静态物使用
Height Fields: 地形
尽可能的使用更简化的shape表达 -
形状属性
Gomboc Shape: 只有一个静平衡点,当质量均匀时会有多个静平衡点。
Mass: 重量
Density: 密度
Friction: 摩擦力
Restitution: 弹力
- 物理世界
Forces: 稳定的力
Gravity
Friction
Drag
Impulse:
冲力
10.2 物理学基础
牛顿第一定律:
在没有其他力的情况下,物体的运动会趋向于匀速直线运动
牛顿第二定律:
加速度与力的大小成正比,与质量成反比
a = F / m
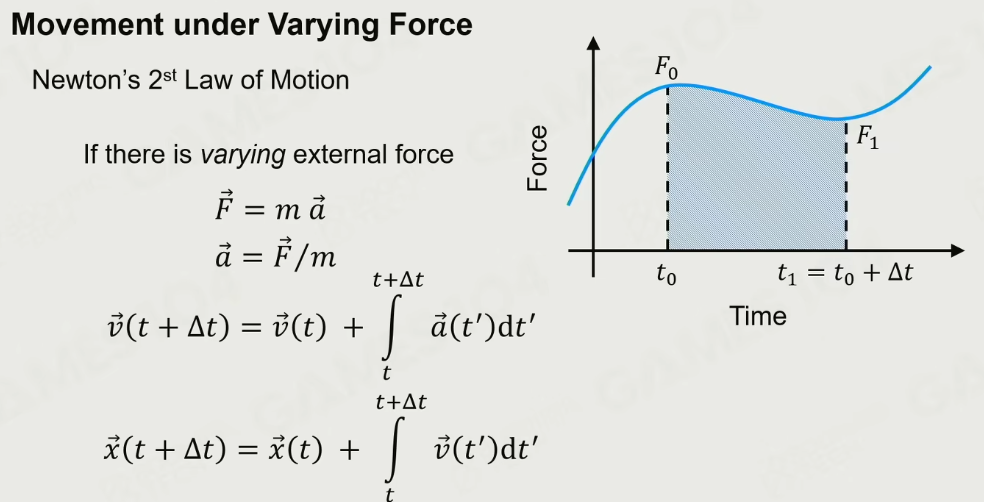
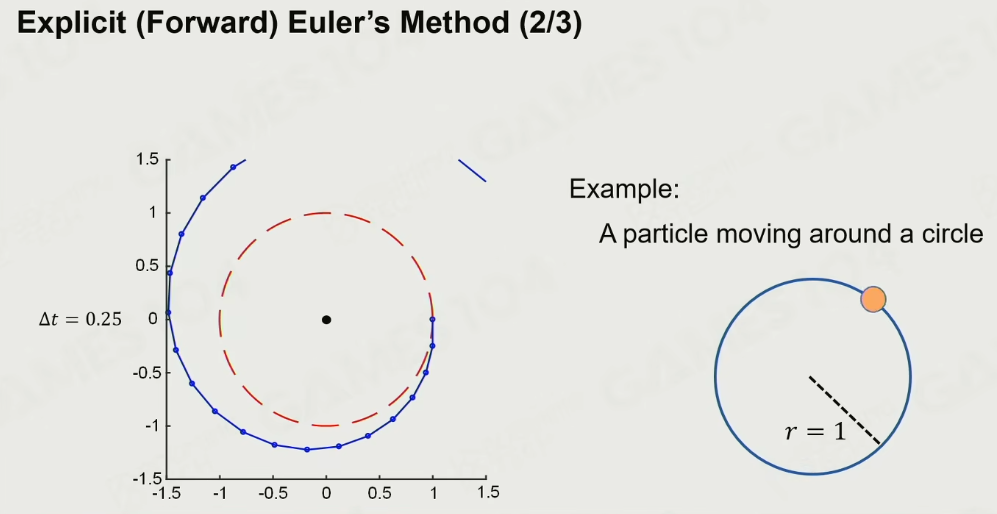
- Explicit(Forward) Euler’s Method
显式Euler积分
核心:
以当前的力和当前的速度,得出加速度,算出下一个时间点的速度
以当前的速度得出下一个位置点
这里的问题是,假定力是constant的,这样能量是不守恒的 且是不稳定的,因此结果是:
步长如果足够小也是可以近似于能量守恒的结果
- Implict(Backward) Euler’s Method
隐式Euler法,力和速度都反向,用未来的速度和力反向计算
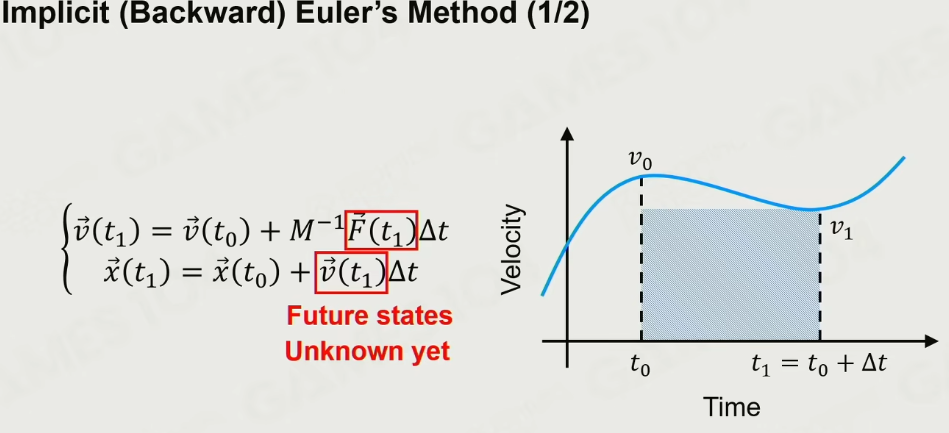
稳定解
但是缺点是 性能耗时, 能量衰减,实现复杂
- Semi-Implict Euler’s Method
半隐式
用未来的速度,但用当前的力

直到198x年才被提出
做单摆,旋转等
一定条件下是稳定的。 简单计算,高效。
问题:
做减弦运动,积分出来的周期会比Ground-Truth略长,导致相位差
10.3 刚体运动学
首先所有的物体假设都有一个旋转,物体都是有原子构成的,可以把原子就看成一个非常小的质点,本身这个旋转是不存在的,但是旋转为什么对刚体有意义呢?
这些离子用各种力束缚在一起,当A要运动的时候,BCD把它束缚住了他们之间的相对关系不能发生变化,所以说一个石头上的每一个原子的话,给一个运动的话它倾向于做的是匀速直线运动,之所以可以转起来其实是内部的力和力的约束造成的,所以说我们讲旋转,一般只是对刚体有价值的。如果是柔体的,则会非常复杂。
- 旋转
基本概念:
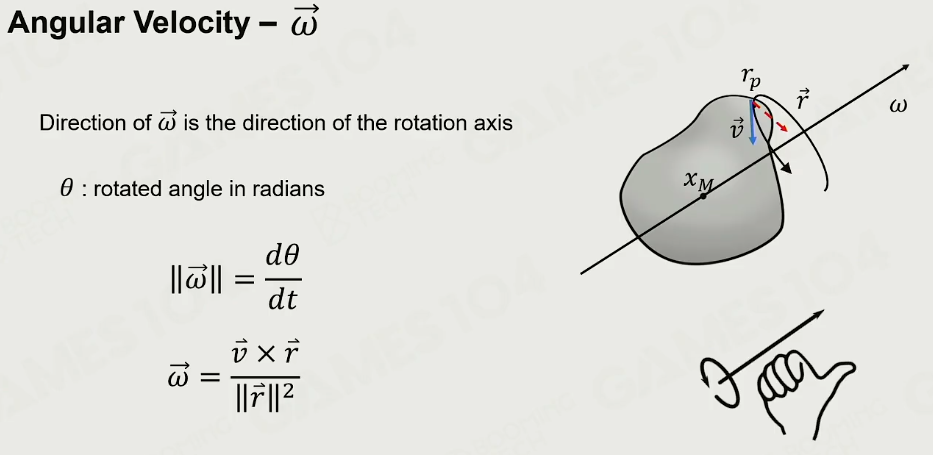
角速度 Angular Velocity: 找任何一个不通过轴心的点,这个点在任何时刻都有一个切向的速度,从那个点连向轴,就有了一个垂直的r向量(下图红色向量),右手法则对v和r做Cross叉积运算,当旋转的时候你会发现,大拇指的方向正好就是旋转轴的方向
角加速度 Angular Acceleration: 角速度的基本上除上时间,但这里假定轴是不变,实际当轴变化时会比较复杂
旋转惯性 Inertia tensor
一个物体放在那里,它的质量是分散在整个形体上的,物体如果绕着自己的质心做旋转的话,整体上看这个物体,它的速度是0,这时候它也有能量,能量在每一个质点自身的运动上面,如果把形体拆成无数个小的质点,那么每个质点都会有一个绕着圆心一瞬间的速度,而且这个速度和它到旋转轴的空间位置有关。简单来讲如果我们讲一个能量,等于0.5 Mv²的话,将这个M拆成无数个小质点,任何一个质量距离旋转轴的半径为2的话,角速度就是2w,那你会发现这个公式变成了0.5 MR²w²,如果将MR²合到一起的话,这个是另一个、【转动惯量】的基础定义。下面这个长方形,绕着不同的轴旋转,转动惯量是完全不同的,长轴会转的快一点,短轴会慢一点
虽然这个解释非常的简单粗暴,实际上【转动惯量】并非一个标量,而是一个3x3的张量
角动量 Angular momentum:守恒,能量是不守恒(虽然游戏世界中能量是守恒的)
力矩Torque: 实际上就是力+一个力臂的长度,是用力的方向,叉乘向转轴中心的轴。 力矩的方向,一定是和旋转轴重合的,朝向的上下指代的就是力矩的方向
10.4 碰撞
第一个阶段: Broad Phase 初筛,做AABB刚体相交检测,预测可能的相交
第二个阶段: Narrow Phase 检测重叠的细节,生成信息
- Broad Phase
BVH
当环境变化时,更新的范围比较小,可以用BVH快速检测可能的碰撞
Sort And Sweep
以每一个bounding的进行轴向的排序,找出重叠的部分
世界中的大部分物体还是静态,对于动态的物体只需要局部更新处理即可。因此这个算法的效率非常高
- Narrow Phase
真正的数学的挑战。需要关注两个相交的物体的交点的个数,深度,相交法线的朝向,就比较复杂。
三种方法:
Basic Shape Intersection Test
对于基础图形来说,求相交。
Minkowski Difference-based Methods
明可夫和:在空间中给了很多个点,假设有一个点集合A、点集合B,点集A里面的每一个点,它都可以和点集B里面的任何一个点相加,相加出来的结果也是一个集合(相同的去重)
对于不同的集合,得到的点集合是不一样,如点是移动,三角形与线是边的拖拉等
给两个凸多面体,他们在空间中包裹的点,他们的【明可夫和】,实际上就是他们所有的顶点的和,在空间中形成的凸包,它们的顶点一一逐对组合,加法形成的点,有些点是在凸包内部,但是凸包就是由这些点构成的,这个特性非常的重要
明可夫差:
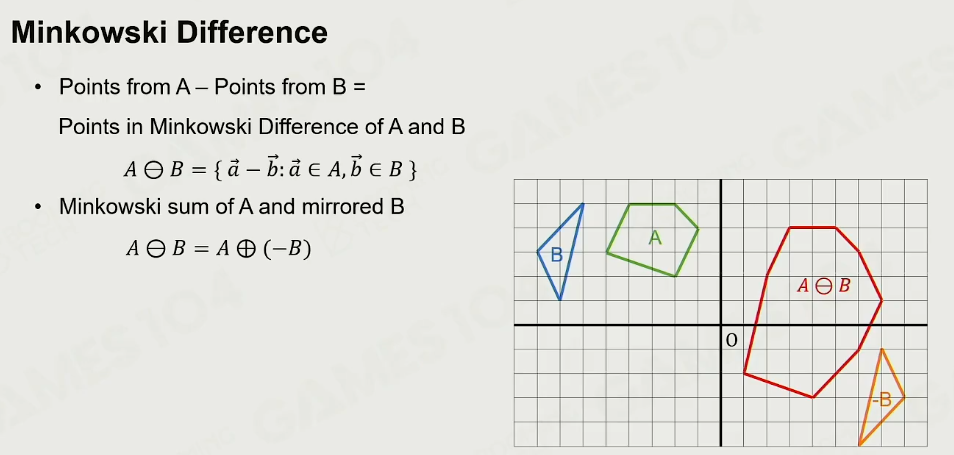
判断过原点:
如果两个物体的明可夫差形成的凸多面体通过原点,则这两个物体必定是相交
- 两个最基础的Collision Detection算法
GJK算法:
先给定一个方向,找到两从此形体在此方向上的端点,此两点的减值得到一个新顶点,以此顶点向原点连线,找出与此线垂线,再去找这条垂线垂直方向的一个点,这个点再去原来形体上找到两个极端的点,这样就形成了一个最简单的Simplex单纯形,就形成了一个三角形,其实就可以判断说原点是否在三角形内部,原点在内就一定相交,如果原点不在内部,就会寻找最靠近外面的一条边,再去和圆心连线去找方向、极端点,等等,将这个单纯形依次往外推,直到推到最外面的边推不动了、推到最后一个边了,还没有找到原点,就说明两个形体是不交集了。
不断的迭代地往原点的趋势去靠的思想
参考视频与实现
既然知道所有的顶点,为什么不直接计算原点是否在其中呢?是因为直接计算是可以的但是计算复杂度非常高,使用【GJK算法】就可以在很快的线性的时间里面,就可以完成交点的判断计算。
而是否在三角形内部的判定只需要算重心坐标即可,计算出的三个值如果都是在(0,1)之间的话说明在三角形内部,如果计算结果出现了一个负1,就表明在外面,其实也非常简单的表达
Separating Axis Theorem(SAT) Convexity
分离轴定理,如果两个凸多面体是没有相交的,那对于在空间上的一个凸多面体,一定能找到一根轴,在这根轴上两个物体的投影一定是分开的。
核心就是:只要找一个分离能分离开,则证明两个物体必定是没有相交的
以一个形体的一条边找到一个分离轴,在这个轴上找另一个形体的顶点。做完此形体后,再检测另一个形体。
在二维空间中,假设它们是分开的话,我一定能够画一条线,把所有的顶点往这条线上投,它们之间是没有交集的。再往深了思考,如果是两个凸多面体的话呢,用凸多面体的边作为一个轴的话,一定能找到一个轴,把这个空间所有的顶点一定在我的左侧、或者在我的右侧,这很符合我们的直觉,如果两个相交的话,这根轴就很难找到。
在三维空间中,则是一个面的关系,但是检测所有的面并不能证明就不相交,还需要检测每一条边形成的面不相交。
那这个如何证明呢?对于任何2个形体的话,对于形体A你找到一条边画一个延长线,再用垂线方向做分离轴,因为是凸多面体,自身的顶点肯定在轴的这一侧,所有的顶点如果都在另外一侧,就表示彼此之间是分离的,就是这个原理
10.5 Collision Resolution
既然已经检测到碰撞了,现在需要处理碰撞后如何让两个物体分开。
三个方式:
- Applying Penalty Force
较早期游戏的做法,简单来说就是各自加个比较大的力将两者分开。现在引擎用的较少。 - Solving Constraints
将力学转成反向约束的数学方式,拉格朗约束。
举一个例子比如说一旦发生了这样的穿插之后,传统的做法是给一个反向的“惩罚力”,另一部分就出去了,这个力给大给小?你根本不知道怎么给比较合适。但是使用【拉格朗日】的方法、解约束的方法,会尝试给它一个小的冲量,这个冲量不是真的把物体移动了,我根据引入的冲量,我再去解拉格朗日的那个约束,解了之后你会发现它还不满足约束,它会有偏差,那么基于这个偏差再去给一个小冲量,再去解【拉格朗日】的约束,这样我就反复迭代,当优化到足够多步骤的时候,我认为这个误差可以接受的时候,就可以输出我的结果
这种不断的迭代冲量的方法,就是现代引擎的Gauss-Seidel方法
物理世界的模拟,很容易做的是不稳定的,需要有一套约束求解器,能够让这个物理世界最后变得稳定下来
10.6 Scene Query
-
Racyast
在物理世界中经常会问,子弹是否能击中目标,这个过程叫做Query,这就是RayCast,其实Ray Tracing的本质就是用RayCast去实现的
一般有三种:
Multiple Hits:一根射线射出去,所有的交点都给我
Closest Hit:最近的交点
Any Hit:不关心子弹射出去之后是否被挡住, 最低的成本 -
Sweep
一个体”扫“过去,比如一个角色在移动的时候,找到哪些被档住 -
Overlap
形成一个新的形体,找到有哪些Actor重叠出来
细节:物理引擎时需要对世界进行分组,Collision Group,哪些是Player, 哪些是Static, Dynamic, Trigger这类。 在做Scene Query也需要对类型进行分类。
10.7 Efficiency,Accuracy,and Determinism
- Island
分组的概念,将整个物理世界分成一个个的Island,好处就是如果一个地方没有更多力的输入,物理所有对象的运动都相对稳定的时候,就会让这个Island给Sleep
所以一个物理引擎性能的好坏,很多时候取决于你去分组,包括让这些物理对象Sleep的水平,这样你才能让你的计算更加集中到你更想表达的东西
-
Continuous Collision Detection
连续碰撞检测:
因为移动速度过快,在当前帧在位置A,到下一帧的位置,其实位置其实已经直接穿过那个障碍物了,因为检测是基于两个形体的检测,所以会发现两个Actor是没有交集的,人就穿过去了,所以这叫做”Tunneling“,隧穿效效应
解法1: 把障碍物做厚做大
解法2: CCD的方法
简单来说就是我们做一个保守的估计,从这个物体到环境中最安全的移动距离是多少,在这个安全移动距离之前随便移动,但是靠近的时候会将步长调密,再做更详细的检测,包括Sweeping其实也能解决这个问题,但是Sweeping很多时候是对简单的胶囊和球起作用,对于Convex确实是要做一些单独的处理,对于和玩家视觉表现直接相关的内容的话,CCD是一个很重要的概念 -
Deterministic Simulation
追求一个确定性原理。 在做物理世界模拟的时候,我们希望的是确定的输入,确定的游戏规则输出的游戏结果是一摸一样的,这就叫做物理引擎的确定性,但实际物理引擎在一个平行宇宙的世界是很难一致的,解决的需求前提:
- 固定的步长
- 迭代算法的顺序一致
- 浮点数的稳定性需要保证
现代物理引擎其实花费了很多时间在解决【确定性】的问题,包括虚幻的Chaos引擎自称可以解决【确定性】的问题,如果物理引擎能够做到确定性,那么ABC客户端彼此之间,不需要同步那么多复杂的物理状态,只需要同步彼此的物理输入,就可以看到一个相同的物理世界。
简单的做法是,动画与渲染的tick速度一致,物理其实是属于logic的tick可能会慢,如果逻辑不敏感的话,甚至15帧也可以
现在的CUDA架构的话,很多物理的计算实际上是可以迁移到GPU上来做,特别是布料模拟,Particle系统,水面模拟,特别是现在的Compute Shader会让这件事变得非常的快,现在有些物理引擎已经有能力使用GPU了,比如说英伟达大力推动PhysicsX,很多算法是可以用CUDA的核去计算,大量的物理运算是可以并行化的
11.物理高级-应用
11.1 Charactor Controller
- 对于动态物理的区别
可控制的刚体
几乎无摩擦力限制
加速和刹车几乎立即改变方向和传送
反物理的系统
- 构建
- Kinematic Actor
Shape: Capsule - 碰撞
Sweep Test,防止离墙太近看到背面的东西
被墙面撞时,沿墙面走 - Auto Stepping 自动抬起在上楼梯
一般会自动抬起一点,但可能会有bug - Slope Limits
光滑斜坡,往下滑 - Controller Volume Update
Controller 形状变更
注意问题:更新时的碰撞问题
Overlap test before update to avoid insertion inside objects - Push
需要支持Hit Callback来与环境互动
当我们制作一个引擎的时候,我们需要把这些接口开放给我们的开发者,让他们自己来选择自己游戏中角色的Style,这也是我们真正使用起来物理世界的第一步
- Ragdoll系统 布娃娃

把关键性的joint挂成ragdoll,一般不超过十几个。
- Ragdoll 约束
以现实中的关节的约束约束joint的变化范围。
一般由TA完成调整
- Ragdoll实现
一个Ragdoll计算出来的结果,反向的去驱动一个Skeleton的话,就是一个Animation ReTargeting过程
对于Skeleton里,分为三类
- Active Joints即骨骼与Ragdoll重合,则这部分需要参与ragdoll运算
- Leaf Joints .还有一些是最后一根Ragdoll骨骼之外,往外延伸的,比如说Ragdoll制作到手的胳膊的地方,手掌之外的手指的这些骨骼, 来是什么Pose我就采取不改动的方式,跟着父级一起运动。
- Intermediate joints。 但是比较麻烦的是,在Ragdoll的RigidBody中的话,中间还有很多根过渡性质的骨骼(上图蓝色点),我们在介绍Animation ReTargeting的时候,其实我们有很多方法,我们可以根据你的动作,把动画这两个Pose之间,一路的插值过去,均匀的分散到各个骨骼上去,实际上在这里Animation ReTargeting是一个非常重要的应用场景,所以中间的我们叫做【Intermediate joints】,它的Pose实际上是从前后两根Ragdoll的Pose之间插值出来的
动画与Ragdoll物理仿真会有一个过渡
- Powered Ragdoll
比较看好引擎中这个的实现,随着对于游戏品质的要求越来越高,我们越来越不满足于,动画师设置好的循环的Animation Loop,更希望用户的输入,游戏的环境给角色带来的更多的随机性和多样性、所以说Ragdoll是一个很重要的基础系统,在它之上有很多很有意思的东西可以衍生
11.2 Cloth
- 旧引擎常用方法
-
Animation-based Cloth Simulation
通过对衣料上添加骨骼
使用DCC工具生成动画数据,优点是简单可控,缺点是不真实,不能与环境交互 -
Rigid Body-based Cloth Simulation
交由Rigid body 处理。 通过Dynamic-bone,通过动力学骨骼做。
优点是简单可交互,缺点是质量不可控,动画师的工作量大,需要高质量的物理系统
- Mesh Simulation
交由Mesh处理
- 不使用Render Mesh,额外创建一个Physical Mesh
- 为Physical Mesh做一个约束权重,如披风靠近脖子部分约束就更大
- 设置Physical Material的参数,如摩擦力,拉力等,模拟出各种衣料
- 使用质点弹簧系统 Mass-Spring System
- damping 阻尼

- 衣料MSS

重力+ 风力+ 空气阻力+ MSS力之合
-
重要的积分方法:Verlet Integration

速度可能在某个时间不稳定,但Verlet把这个问题避开了,且更高效。
思想上与半隐式Euler积分一样 -
使用Poistion Based Dynamics
现在主流的算法实现布料
-
Self Collision
布料相互之间,或者是和rigidbody之间重合穿插的问题,自我碰撞的问题
通用解决方案:
- 布料加厚
- 物理计算时step动态变更
- 设置一个maximal velocity, 让穿插之后,以此速度之内的物体还能弹回来。
- 设置一个负向布料力场,SDF会有一个反向的力往外
11.3 Destruction
破坏系统
-
Chunk Hierachy
对物体进行分块,自动对物体切分成各个碎片 -
Connectivity Graph
对每一个chunk的边制作硬度数值,决定以多少冲量会让两个碎片之间断开 -
破坏计算


-
Support Graph
决定哪一部分会受到破坏效果 -
如何生成chunk呢?
Voronoi Diagram
- 空间随机产生一些种子
- 以空间的距离以一定速度往外扩张
- 如何解决材质问题?
断口处的纹理生成的问题:
- 有一套procedure方法,生成3D Texture
- 离线生成好断口处的材质
-
碎片的物理问题?
一般游戏来说并不会把碎片的物理参与到LOGIC系统中。
以各种各样的形式破坏等,引擎中内置,如unreal中 -
破坏的配套系统
添加更多的callback为声效,特效的添加,寻路导航系统更新做准备 -
破坏系统的问题
- 碎片的无休止产生,导致性能极大的负载,对算力的需求极大
- 更多的还是存在艺术家的经验上,同时性能的问题还是取决于工具链
- 主流的破坏实现
NVIDIA APEX Destruction
Havok Destruction
Chaos Destrution- Unreal 号称性能最强,使用不多
11.4 Vehicle-载具系统
引擎也会提供相关的接口
-
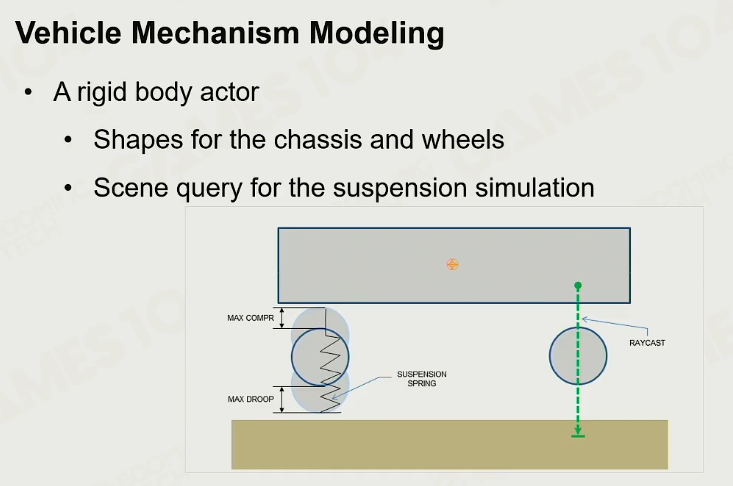
汽车机械模型化
-
驱动力
差速器:把扭矩分配到各个轮子
Torque 扭矩
轮胎只要不打滑,不漂移,始终是静摩擦力
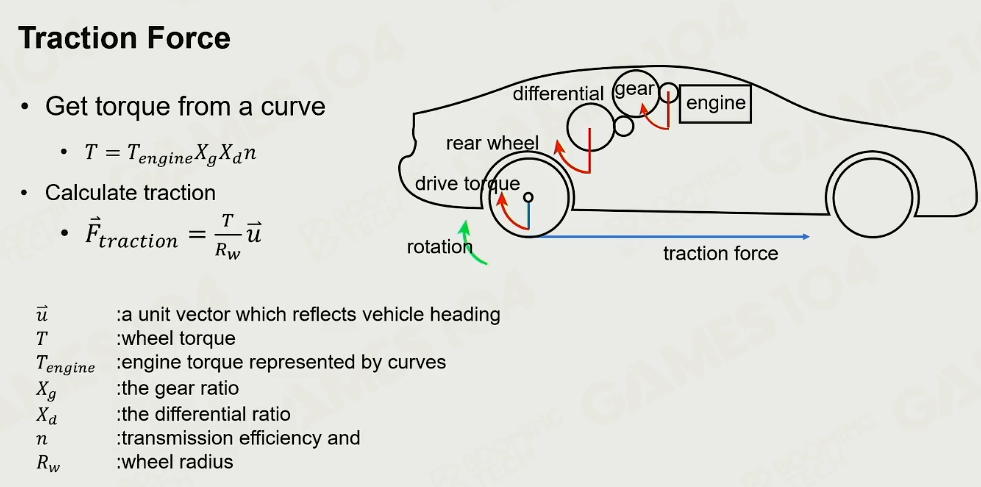
-
悬挂力
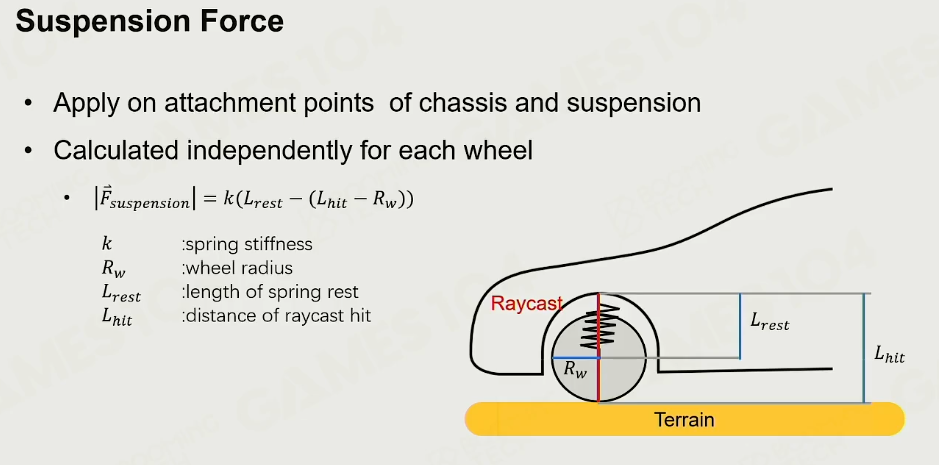
-
轮胎力
导向轮: 沿着前轮的阻力
驱动轮:还要多一个引擎驱动力
当轮胎打方向时:产生切向力,这是一个滑动摩擦力,受制于摩擦系数,也受制于重心
当解一个车的导向方程时,需要分开解这两个力。

-
重心 Center of Mass
汽车的重心点。
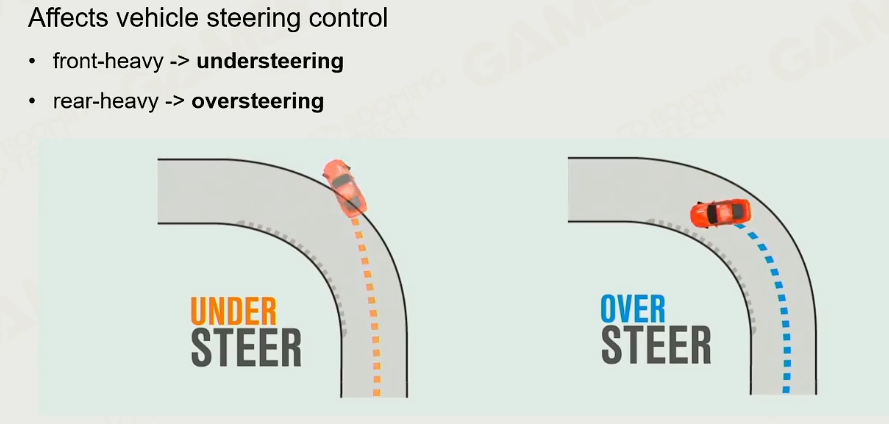
- 对于一些前驱车,前轮又是导向轮又是驱动轮,这样车的转向力会较差。
- 对于重心太前,会更容易dive,往后,则会更稳定
- 重心太前,汽车转弯时转向力不足,导致扭矩不足。
加速对于重心的变化
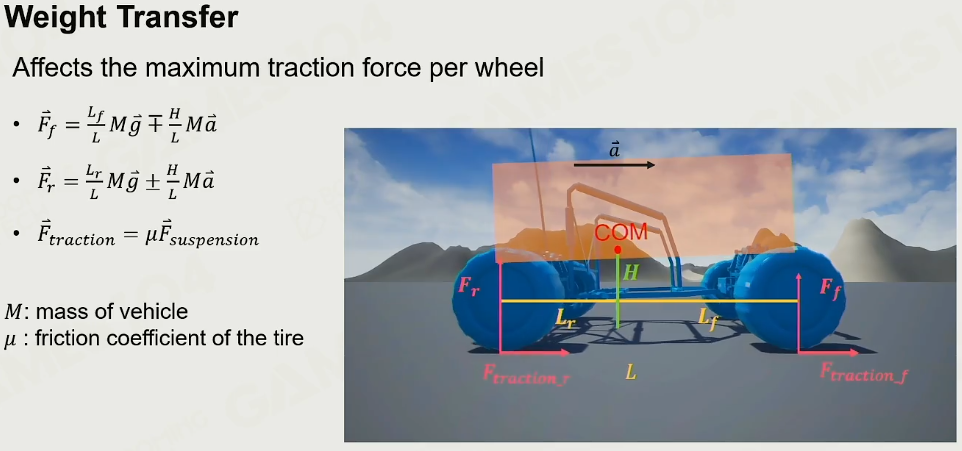
-
汽车的转向角
转向角实际上表达的意思是,如果汽车的两个导向转,假设都打一样方向角的时候,外侧的轮实际上是空转的、即被拖着走的,它本身的转向力是不足的,所以它有一个数学的方法,内测的轮它实际上转向的更多一点,外侧的相对小、它指向的是一个很远的旋转中心,以它那个连接线作垂线决定角度。因为车本身就是有宽度的,车和人不同,转动时候由于车是刚体要考虑宽度,这个Ackermann转向角的话,也是考虑到了这一点,也就是相对两个轮胎,前后关系是不会发生变化的,所以这个时候,当你想让转向的时候,两边的导向轮最大限度的发挥它的转向作用的时候,实际上是有一个小小的角度差的(下图l和r实际上写反了)
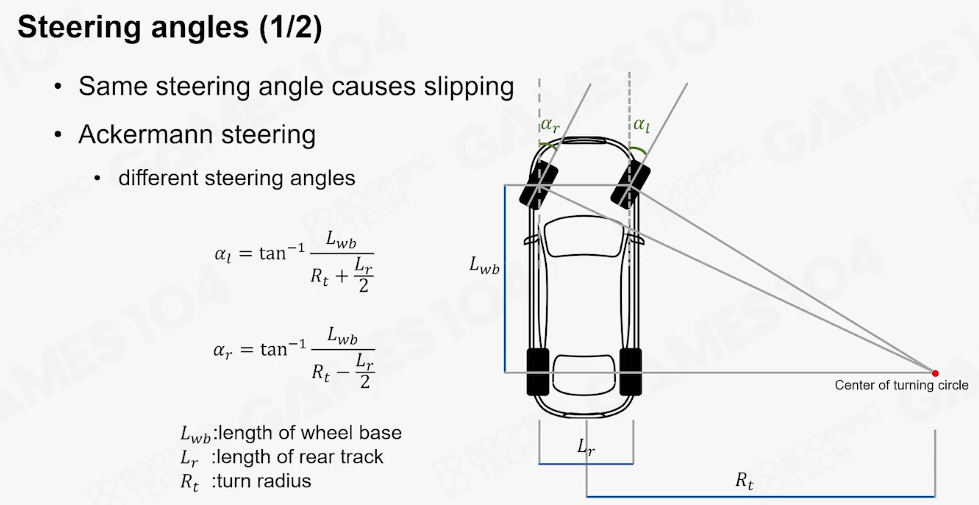
-
使用Spherecast来模拟轮胎
11.5 PBD/XPBD
从数学上看牛顿力学上看并不美妙,这样就有一套完全不一样的力学, 拉格朗日力学。
简单来说: 所有的运动规律,都可以被这些约束反向的求解回来
对我们的帮助就是把很多力学的计算,变成了求解约束的问题
- 例:绕圆旋转为例

Jacob矩阵:表达的是一个趋势的变化量。 一个对约束的一个导数,告诉下一步尝试,以这个方向尝试就能最快的达到那个点
那么对于【弹簧质点模型】里面,也同样可以使用这种约束去表达,当你有两个质点x1和x2的时候,两边都可以乱动,但是中间需要满足restpose,实际上它的约束就是x1-x2,即两点之间的距离、也就是模长,减去restpose的距离,等于0,这就是对于一个弹簧的约束
- PBD
有了这些约束之后,怎么去迭代,寻找那个点呢?
假设所有的点都在这个空间上,实际上所有约束为0的状态,以下图右侧为例就是实线的形状,但是如果说现在是在最外面的一个点,你会发现,求出这个函数的雅可比矩阵,就知道这个倾向性是什么、往哪里去指,接着就要猜测我的步伐,当永远沿着方向走一个我认为的步长,去逼近所有的约束都为0的那个点。这个在求解IK的时候也是一样的,当我的人身上含有很多的Joint,每个Joint都会自己动,当某个Joint移动的某个位置,你可以理解成每个Joint都试图动一下,用雅可比矩阵他就会告诉我一个趋势:如果某个Joint想到某个点的话,另一些Joint得收起来,一些Joint需要去打开,这个时候就能达到目标位置。实际上雅可比矩阵可以算出当前姿态下,你要想靠近你的目标点,每一个变量扰动的趋势是什么,但是这个趋势当你的扰动量变大的时候,这个趋势就不准了,所以它才会有一个步长的计算
最核心的思想就是我们不去计算速度、加速度、力,什么都不算,我们只将所有的物理的系统,描述成一系列复杂的关于你位置的约束,以布料为例,本质上是由一系列的约束构成的,那么使用雅可比矩阵,去计算每一个在当前的Pose下,应该向着哪个方向扰动,一直扰动,当然每一次动一点点之后再去计算,是否满足这个约束,如果不满足的话将这个过程再重复一遍
对于这个PBD的理解,在我看来就是一个【Super牛顿迭代法】,但是核心思想使用的是【拉格朗日力学的方法】,就是说将碰撞、惯性、加速度,全部变成一组约束的矩阵,然后计算出趋势,沿着趋势去不停的扰动你每个顶点,类似一圈圈套圈去逼近这个结果,是一个迭代式算法,PBD最核心的点在于说,它将核心的物理学规律都抽象成了约束,在之前解牛顿力学的速度也好、加速度,会导致Iteration、Simulation不稳定的东西,给它优化掉
优点:
以隐式约束去解,快速,稳定,在布料系统中是非常重要的方法
- XPBD
UE5中Chaos号称使用了XPBD
理解为是PBD的优化,在中间引入了一个叫做“stiffness 刚性”的量,即这个约束到底是一个【硬约束】还是一个【软约束】,如果stiffness数值等于0,那么它的导数就是无穷大;如果这个东西是软软的则可以有足够的弹性误差,stiffness相对小一点,所以它在公式中通常使用的都是a的-1次方,它的导数去做

土一点的理解,你可以把这个约束想成是一个弹簧,stiffness可以理解为弹簧的硬度,stiffness等于0的时候弹簧硬度就无穷大,导数就是胡克常数,那么C(X)就是偏移量(可以理解成位移),那么一个弹簧误差偏移量多少的时候,就是0.5kx平方
一个弹簧所存储的势能,就是你把他从restpose拉开来位移的平方,但是如果这不是一个一维的弹簧、是一个多维系统的时候,实际上约束就会变成一个矩阵的形式,矩阵乘以矩阵转置,中间再来一个stiffness的话,实际上从数学的逻辑上,就是说系统内含的一种势能,本质上就是让你优化这个势能足够的小,但是这个XPBD好处是可以给逐条的约束,增加它的stiffness
11.6 问题
- 布娃娃“鬼畜”
- Joint约束没做好。
- ragdoll进入到一个静态Actor,而这种actor的质量和动量是无穷大的,这样的物理仿真是不稳定的。
所有的物理结算现在都是Iteration,但是真正好的物理引擎、做物理引擎功能很高深的开发,知道什么时候Stop Iteration,Stop做的不好的话就会出现一半卡住了,一旦卡上去了后面给它加上再大的力,在物理引擎中也是无法将它们再分开的,很多时候要Hack它们分开了,之前经常在做角色的时候物理仿真没解决好,一个角色就卡在一个地方,也是这个原因。所以Ragdoll的话,所有的Actor的运动,全是交给物理模拟的,所以很有可能卡在一个地方,很有可能产生一些没有办法Dumpling掉的奇怪速度量、惯性量,在系统中来回的震荡
- 爆炸和可破坏物体交互:
分两步:
- 爆炸区域沿着中心衰减的一个冲量场,当有一个可破坏物体,检测到了在爆炸区域中以后,可以根据距离爆炸中心的距离,计算出冲量
- 有了冲量可以根据Hardness可以计算出破坏的系数是多少(冲量/Hardness),数值大于预设的Chunk之间的Connection的话,就会发生碎裂或者破坏了
 wechat
wechat alipay
alipay