Python 杂项
Python 杂项
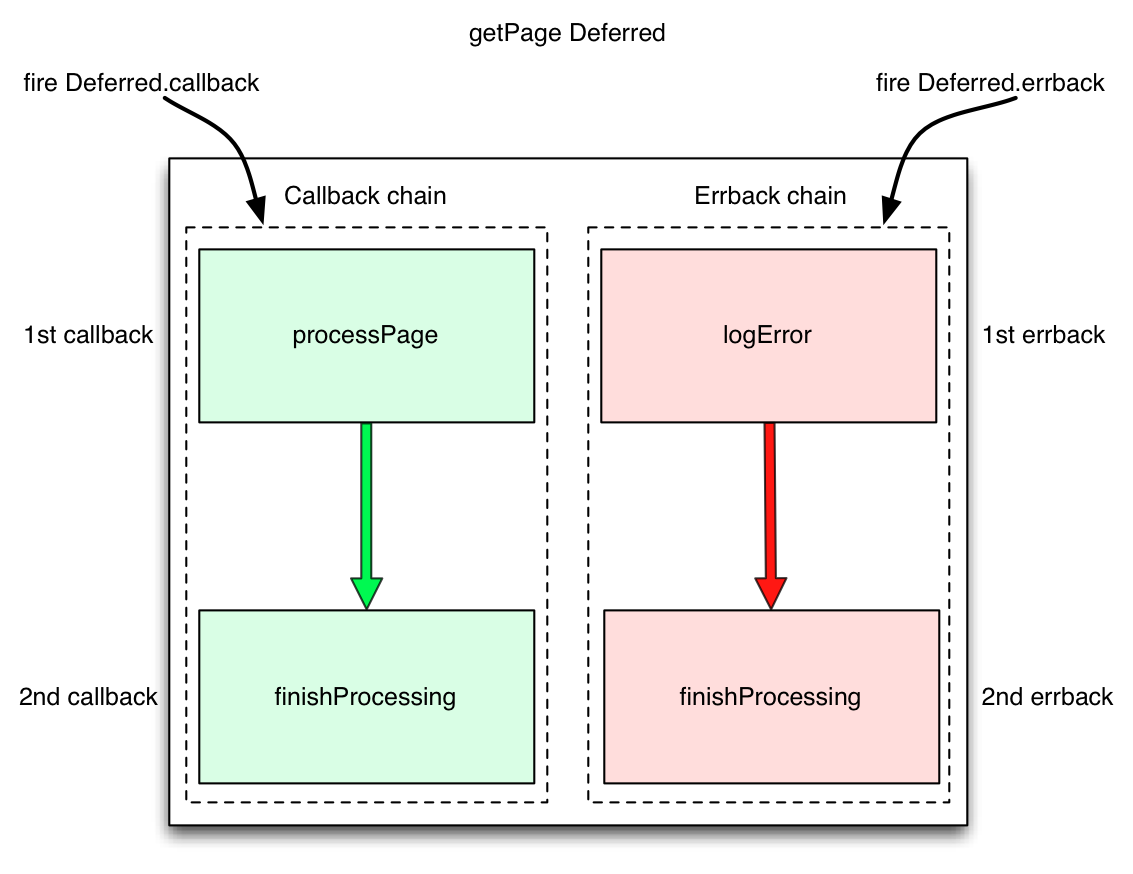
关于 *args 和 **kwargs参数的用法
- 允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。
def f(a,*args): |
** ,关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def d(**kargs): |
关于多线程与多进程
作者:DarrenChan陈驰
链接:https://www.zhihu.com/question/23474039/answer/269526476
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在介绍Python中的线程之前,先明确一个问题,Python中的多线程是假的多线程! 为什么这么说,我们先明确一个概念,全局解释器锁(GIL)。
Python代码的执行由Python虚拟机(解释器)来控制。Python在设计之初就考虑要在主循环中,同时只有一个线程在执行,就像单CPU的系统中运行多个进程那样,内存中可以存放多个程序,但任意时刻,只有一个程序在CPU中运行。同样地,虽然Python解释器可以运行多个线程,只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同时只有一个线程在运行。在多线程环境中,Python虚拟机按照以下方式执行。
1.设置GIL。
2.切换到一个线程去执行。
3.运行。
4.把线程设置为睡眠状态。
5.解锁GIL。
6.再次重复以上步骤。
对所有面向I/O的(会调用内建的操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其他线程在这个线程等待I/O的时候运行。如果某线程并未使用很多I/O操作,它会在自己的时间片内一直占用处理器和GIL。也就是说,I/O密集型的Python程序比计算密集型的Python程序更能充分利用多线程的好处。我们都知道,比方我有一个4核的CPU,那么这样一来,在单位时间内每个核只能跑一个线程,然后时间片轮转切换。但是Python不一样,它不管你有几个核,单位时间多个核只能跑一个线程,然后时间片轮转。看起来很不可思议?但是这就是GIL搞的鬼。任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
作者:yegle
链接:https://www.zhihu.com/question/23474039/answer/24695447
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如果你的代码是CPU密集型,多个线程的代码很有可能是线性执行的。所以这种情况下多线程是鸡肋,效率可能还不如单线程因为有context switch但是:如果你的代码是IO密集型,多线程可以明显提高效率。例如制作爬虫(我就不明白为什么Python总和爬虫联系在一起…不过也只想起来这个例子…),绝大多数时间爬虫是在等待socket返回数据。这个时候C代码里是有release GIL的,最终结果是某个线程等待IO的时候其他线程可以继续执行。反过来讲:你就不应该用Python写CPU密集型的代码…效率摆在那里…
如果确实需要在CPU密集型的代码里用concurrent,就去用multiprocessing库。这个库是基于multi process实现了类multi thread的API接口,并且用pickle部分地实现了变量共享。再加一条,如果你不知道你的代码到底算CPU密集型还是IO密集型,教你个方法:multiprocessing这个module有一个dummy的sub module,它是基于multithread实现了multiprocessing的API。
假设你使用的是multiprocessing的Pool,是使用多进程实现了concurrency
from multiprocessing import Pool
如果把这个代码改成下面这样,就变成多线程实现concurrency
from multiprocessing.dummy import Pool
两种方式都跑一下,哪个速度快用哪个就行了。
刚刚才发现concurrent.futures这个东西,包含ThreadPoolExecutor和ProcessPoolExecutor,可能比multiprocessing更简单
作者:find goo
链接:https://www.zhihu.com/question/23474039/answer/132530023
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
多线程还是有用的,多进程有多进程的好处,多线程有多线程的好处。多进程稳定,启动时开销大点,但如果你的运行时间远大于多进程的时间,用多进程比较方便,如postgresql用多进程,chrome 多进程。如果你只是想做个定时器样的简单东西,对稳定性要求低些,如vb,c#类似的定时器,用多线程吧,但线程的同步要注意了。python的线程更加类似定时器,python的线程不是真线程,但有的场合用这种定时器也能解决很多问题,因为开销小,开启也方便。进程和线程,一个是重量级的,一个轻量级的,重量级的进程有保护区,进程上下文都是操作系统保护的,而线程是自己管理,需要一定的技术,不能保证在并发时的稳定性(多进程也不稳定,但很容易看出来,因为多出了进程容易发现),而python的更像是定时器,定时器有时也可以模拟线程,定时器多时的开销比线程的开销要小,真线程有下上文开销,一个操作系统启动多进程和多线程会达到切换饱和是有数量的,真线程或进程太多都会导致cpu占用率居高不下,而定时器可以开n多。很多东西不是一种比另外一种先进,而是一种互补的关系,计算机的计算单位切换有优点必有缺点,关键在找到合适的使用方式扬长避短。
参考教程
 wechat
wechat alipay
alipay