Python源码剖析-Note2
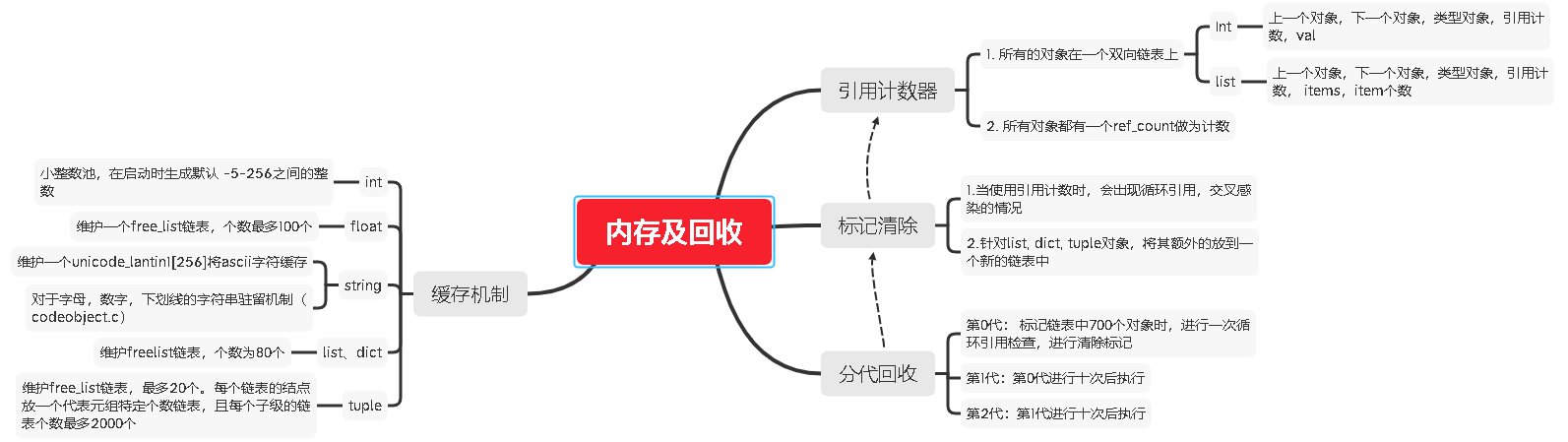
Python的内存
引用计数
由源码可知,Python的数据对象由PyVarObject(PyObject+size)组成,PyObject中又包含了双向链表,计数器,数据类型_typeobject对象(其中可以定制行为)
/* Define pointers to support a doubly-linked list of all live heap objects. */ |
标记清除
对于list, dict, tuple 这种类型,有可能存在循环引用的情况,这时需要再做一次扫描及标记清除的处理。
- 在Python中使用另一个新的链表来存储需要标记清除的对象。然而这种扫描的往往比较耗时,需要执行可达性分析,以找到unreachable的对象,对这些对象进行标记清除。
- 因此为标记清除的处理需要找一个时间点来。 这就引入了分代机制
分代机制
标记清除的扫描的操作比较耗时。所以需要设置一个时间点。
- Python中设置第一代为 700个对象, 第二代为第一代的10次,第三代为第二代的10次
- 可使用python的gc模块,从业务层对这些值进行设置
缓存机制
一、int的缓存机制
二、字符串的缓存机制:
-
intern dict : PyDict对象,key, value就是字符串
-
nullstring, characters, 空串和单串,有两个属性来存储
intern的默认识别只能在compile时,无法在runtime时识别,不过可以手动调用intern

三、tuple的缓存机制
PyTupleObject, 维护一个链表,用free_list存储链表头, 20个
不用像int和string一整块的申请,利用链表的ob_item组起来
四、list的缓存机制
维护一个free_list , 保存80个,运行时往里回放。
四、源码分析
obmalloc.c -> PyObject_Malloc
-
申请大小大于256,直接使用 PyMem_Malloc
-
小于256, 进入小块内存池
- 取size, 指定大小-1 后 除以8或者16字节。(设定一个block大小)
总结
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Avery的城堡!
 wechat
wechat alipay
alipay
相关推荐
2022-05-19
Python源码剖析-Note1
1.Python 架构 1.1 文件组: 模块、库、自定义模块 1.2 核心 解析器 Scanner词法分析 -> Parser语法分析,建立AST(抽象语法树) -> Compiler 生成指令集合,Python字节码(byte code) -> 由Code Evaluator(虚拟机)执行字节码 1.3 运行时环境 对象/类型系统 Object/Type structures 内存分配器 Memory Allocator 运行时状态信息 Current State of Python 2.Python的内建对象 2.1 关于对象 类型对象(整数类型,字符串类型)都是被静态初始化的 对象被创建后的内存中的大小是不可变的! 2.2 PyObject 只包含一个引用计数和一个类型指针(指向具体的结构信息) /* PyObject_HEAD defines the initial segment of every PyObject. */#define PyObject_HEAD \ ...
2022-05-19
Python Core Programming Note 1
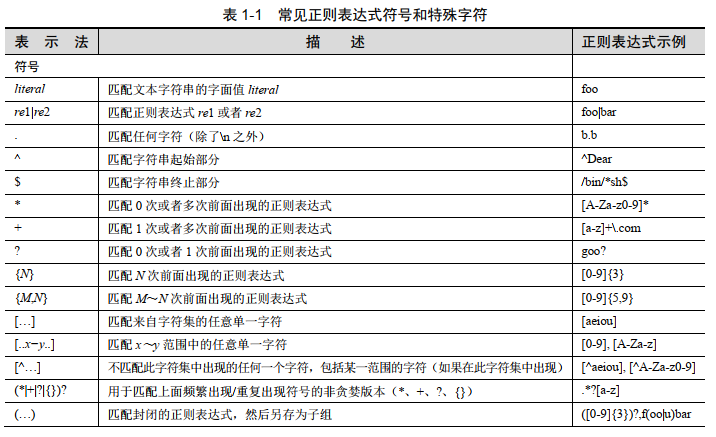
Regular Expression match() & search() import rem = re.match('\d','a541')if m is not None: print(m.group())else: print("none found") ## none foundimport rem = re.match('\d','a541')if m is not None: print(m.group())else: print("none found") ## 5 import rem = re.search('..[\d]{1,3}','\na51')if m is not None: print(m.group())else: print("none found")# . 匹配除\n外的任意字符,其他如\t,\.都...
2022-05-19
Python Note 3
Python Note 3 Classes Use Pacal naming convertion,not like variables/function use lower cases and underscore connection. Basic usage: class Point: def draw(self): print("draw") def print(self): print("this is point")point1 = Point()point1.x = 5point1.draw()print(point1.x) Constructor class Point: def __init__(self, x, y): self.x = x self.y = y def draw(self): print("draw") def print(self): print("this is point")point1 = Point(10, 5)point1.draw()...
2022-05-19
Django 实例 Web Application
Preparing Python Django Html css Javascript Databases HeroKu Materialize Beautiful suite Web scraping Starters! 创建conda环境 conda create --name codedaddies python=3 安装django pip install django 创建工程(指定目录下) django-admin startproject codedaddies_list 创建APP python manage.py startapp my_app 数据库构建 python manage.py makemigrationspython manage.py migrate Templates文件夹 配置在settings中,加入以下: TEMPLATE_DIR = os.path.join(BASE_DIR, “templates”) 底部加入: STATICFILES_DIR = (os.path.join(BASE_DIR, ‘sta...
2022-05-19
Python Note 5
Python Note 5 kwargs的使用 kwargs表示有key, value形式的参数,如: def test(*args,**kwargs): print "args:", args print "kwargs", kwargstest(12,2,abc={"good":7})# 输出:# args: (12, 2)# kwargs {'abc': {'good': 7}} 使用Pop取出kwargs的值 def test(*args,**kwargs): print "args:", args print "kwargs", kwargs val1 = kwargs.pop('abc', False) print "kwargs val:", val1 if kwa...
2022-05-19
Python Note 1
Python Note 1 逻辑运算符的使用: and or not 会将几个值作为False :0 None “” [] 多变量赋值 minValue, maxValue = 10 , 20 命名规范 变量名,函数名: 小驼峰或下划线小写的形式 常量:全大写 类名:大驼峰 代码换行: 当一行写不完时,使用 \ 将代码延续 product = max(100,200) \ *30 输出: 以% 输出 字符宽度指定:“%3d” 右对齐数字, “%-3d”左对齐数字。换成s则为字符串。 小数精度指定:%<field_width>.f ,注意字符宽度将包含. a = 10print("%d"%a)b = 100.025print("%0.2f"%b)print("%-10.3f"%b) 自动转义的函数 “greater”.len() 等价于len(“greater”) “a”+“b” 等价于"a".add(“b”) “e...