Python Core Programming Note 1
Regular Expression
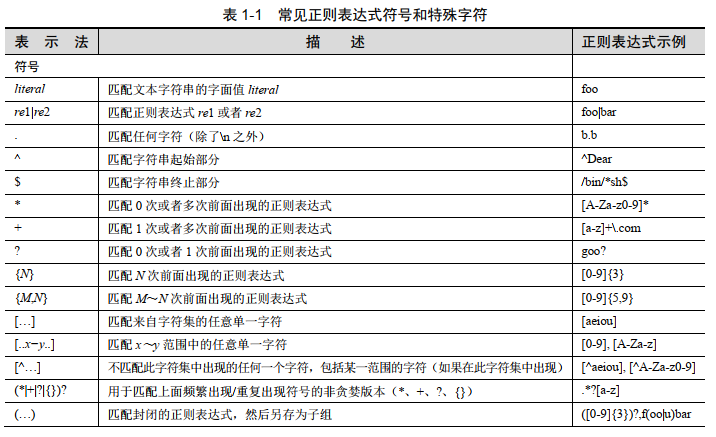
match() & search()
import re |
import re |
分组
import re |
sub() & subn()
#使用函数作为参数 |
Regular Expression -> Split()
data = ( |
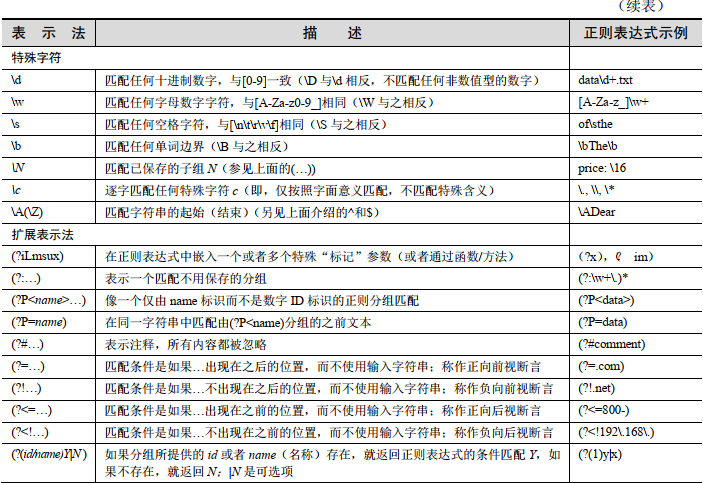
扩展表达式
// 前瞻:
exp1(?=exp2) 查找exp2前面的exp1
// 后顾:
(?<=exp2)exp1 查找exp2后面的exp1
// 负前瞻:
exp1(?!exp2) 查找后面不是exp2的exp1
// 负后顾:
(?<!exp2)exp1 查找前面不是exp2的exp1
要理解?:则需要理解捕获分组和非捕获分组的概念:
()表示捕获分组,()会把每个分组里的匹配的值保存起来,使用$n(n是一个数字,表示第n个捕获组的内容)
(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来
m = re.findall(r'(?<!YES)yes','YESyes? YESYes . YESyesYES!! ') |
?i ignorecase
?m multi-line search
?s dotall, 点号也可表示\n
?x 格式化正则中的空格
?: 分组查询但不保存在结果中
m = re.findall(r'(?m)(^th[\w ]+)', """ |
m = re.search(r'''(?x) |
m = re.findall(r'http://(?:\w+\.)*(\w+\.com)','http://google.com http://www.google.com http://code.google.com') |
贪婪与非贪婪
一个方案是使用“非贪婪”操作符“?”。读者可以在“*”、“+”或者“?”之后使
用该操作符。该操作符将要求正则表达式引擎匹配尽可能少的字符。
data = 'Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8' |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Avery的城堡!
 wechat
wechat alipay
alipay
相关推荐
2022-05-19
Python Core Programming Note 2
Net Programming 1. TCP Server: from socket import *from time import ctimeHOST = ''PORT = 21111BUFSIZ = 1024ADDR = (HOST, PORT)tcpSerSocket = socket(AF_INET, SOCK_STREAM)tcpSerSocket.bind(ADDR)tcpSerSocket.listen(5)try: while True: print("waiting for connection...") tcpCliSocket, addr = tcpSerSocket.accept() print("connected from :",addr) while True: data = tcpCliSocket.recv(BUFSIZ) if not data: ...
2022-05-19
Python Core Programming Note 3
Multi-thread Python 的 threading 模块 Python 提供了多个模块来支持多线程编程,包括 thread、 threading 和 Queue 模块等。程 序是可以使用 thread 和 threading 模块来创建与管理线程。 thread 模块提供了基本的线程和锁 定支持;而 threading 模块提供了更高级别、功能更全面的线程管理。使用 Queue 模块,用户 可以创建一个队列数据结构,用于在多线程之间进行共享。 核心提示:避免使用 thread 模块 推荐使用更高级别的 threading 模块,而不使用 thread 模块有很多原因。 threading 模 块更加先进,有更好的线程支持,并且 thread 模块中的一些属性会和 threading 模块有冲突。 另一个原因是低级别的 thread 模块拥有的同步原语很少(实际上只有一个),而 threading 模块则有很多。 不过,出于对 Python 和线程学习的兴趣,我们将给出使用 thread 模块的一些代码。 给出这些代码只是出于学习目的,希望它能够让你更好地领悟为什么应...
2022-05-19
Twisted 介绍
Twisted Python Twisted介绍 Twisted是用Python实现的基于事件驱动的网络引擎框架。Twisted诞生于2000年初,在当时的网络游戏开发者看来,无论他们使用哪种语言,手中都鲜有可兼顾扩展性及跨平台的网络库。Twisted的作者试图在当时现有的环境下开发游戏,这一步走的非常艰难,他们迫切地需要一个可扩展性高、基于事件驱动、跨平台的网络开发框架,为此他们决定自己实现一个,并从那些之前的游戏和网络应用程序的开发者中学习,汲取他们的经验教训。 Twisted支持许多常见的传输及应用层协议,包括TCP、UDP、SSL/TLS、HTTP、IMAP、SSH、IRC以及FTP。就像python一样,Twisted也具有“内置电池”(batteries-included)的特点。Twisted对于其支持的所有协议都带有客户端和服务器实现,同时附带有基于命令行的工具,使得配置和部署产品级的Twisted应用变得非常方便。 为什么需要Twisted 2000年时,Twisted的作者Glyph正在开发一个名为Twisted Reality的基于文本方式的多人在线游戏。这...
2022-05-19
Centos 部署 Django
1. 下载必要库 yum -y groupinstall "Development tools" 2. 下载最新SQLITE 到SQLite官网的下载页面:https://www.sqlite.org/download.html 这里是最新的版本,我们就安装它吧。 wget https://www.sqlite.org/2017/sqlite-autoconf-3160200.tar.gztar zxvf sqlite-autoconf-3160200.tar.gzcd sqlite-autoconf-3160200./configuremakesudo make install 以默认方式安装后,会把编译好的二进制文件安装到 /usr/local/lib, 把头文件sqlite3.h sqlite3ext.h安装到/usr/local/include。 用这两条命令确认一下已成功安装到这里: ls -l /usr/local/lib/*sqlite*ls -l /usr/local/include/*sqlite* 3.Python 安装 wget htt...
2022-05-19
Python Note 4
Python Note 4 Pypi & Pip pypi use as : pip install openpyxl to install Use openpyxl import openpyxl as xlfrom openpyxl.chart import BarChart, Referencewb = xl.load_workbook("pydemo2/transactions.xlsx")sheet = wb["Sheet1"]for row in range(2, sheet.max_row + 1): cell = sheet.cell(row, 3) real_val = cell.value * 0.9 real_val_cell = sheet.cell(row, 4) real_val_cell.value = real_valvalues = Reference(sheet, min_row=2, max_row=sheet.max_row, min_col=4, max_col...
2022-05-19
Django 初步构建
Generic View 简化写法,可选的有generic.IndexView和generic.DetailView DetailView 默认使用 <app name>/<model name>_detail.html.为模板, 可使用template重定向。自动生成model小写名字_list 为名的对象 ListView 默认使用 <app name>/<model name>_list.html 为模板,可使用template重定向。 自动生成model小写名字的context对象