GEA-P4
5 引擎的支持系统
(5.1) 子系统的启动与关闭
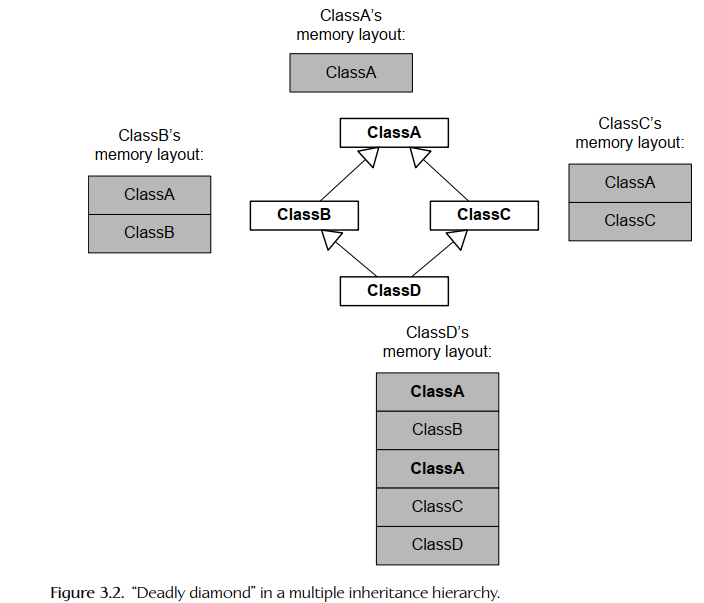
游戏引擎由若干子系统组成,在启动时如果系统间有相互依赖,同销毁时的顺序也需要按要求。如B系统依赖A,则A需要先启动再启动B,销毁时则是B先销毁再销毁A。
处理各子系统启动关闭的方式
-
- 单例模式: 第一次使用时,构造函数中初始化所依赖的其他子系统
-
- 【推荐】使用另一个管理器,统一管理所有的子系统启动与关闭。
(5.2) 内存管理
内存影响性能的两个方面:
- 动态内存分配 :malloc或new。将比较低效,可以避免一次性分配
- CPU内存的高效性与普通大内存
5.2.1 优化动态内存分配
规则: Keep heap allocations to a minimum, and never allocate from the heap within a tight loop.
效率低下的原因: 1. 堆分配器的管理消耗。 2. 大部分操作系统free()函数调用需要切换模式。(用户切到内存,再切回来)
保证越少分配越好,从不要在update中申请堆内存。
5.2.1.1 自定义动态内存分配器
- Stack -Based Allocators 以栈为基础的分配器
-
许多游戏以类似栈的方式分配内存。每当一个新的游戏关卡被加载时,内存就会被分配给它。一旦加载了该级别,就很少或不进行动态内存分配。在这一层的最后,它的数据被卸载,它的所有内存可以被释放。对于这些类型的内存分配,使用类似栈的数据结构是很有意义的。
-
栈分配器是非常容易实现的。我们简单地使用malloc()或global new分配一个大的连续内存块,或者通过声明一个全局字节数组(在这种情况下,内存是从可执行文件的BSS段中有效分配的)。维护一个指向栈顶部的指针,这个指针下面的所有内存地址被认为是在使用中,而它上面的所有地址被认为是空闲的。顶端指针被初始化为栈中最低的内存地址。每个分配请求只是将指针按请求的字节数向上移动。只需将顶部指针按blockIt的大小向后移动,就可以释放最近分配的块。
-
要意识到,对于栈分配器,内存不能以任意顺序释放。所有释放必须按照与分配它们相反的顺序执行。执行这些限制的一种简单方法是根本不允许释放单个块。替代的方案就是,我们可以提供一个函数栈顶部回滚之前标记位置,从而释放之间的所有块当前最高和回滚位置。
-
非常重要的一点是,要总是将顶部指针回滚到两个分配好的内存块中间,否则新分配将覆盖最顶部的块的末端。为了确保正确地执行此操作,堆栈分配器通常提供一个函数,该函数返回表示堆栈当前顶部的标记。回滚函数然后将这些标记中的一个作为其参数。如图所示。栈分配器的接口通常看起来像这样。
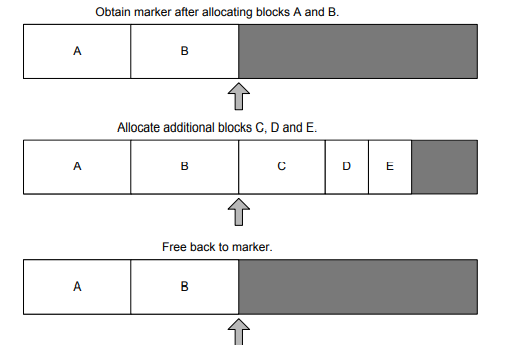
Double ended stack allocator 双端栈分配器
- 单个内存块实际上可以包含两个栈分配器——一个从块的底部向上分配,另一个从块的顶部向下分配。双端栈分配器很有用,因为它允许在底层栈的内存使用和顶层栈的内存使用之间进行权衡,从而更有效地使用内存。在某些情况下,两个栈可能使用大致相同的内存,并在块的中间相遇。在其他情况下,两个栈中的一个可能会比另一个栈消耗更多的内存,但是只要请求的内存总量不大于两个栈共享的内存块,所有分配请求仍然可以得到满足。

- 池子为基础的分配器: Pool Allocators
- 预先申请一块大的内容,将元素放在一个链表结构上。
- 初始时池子里链表空闲位是满的,当使用一个时,获取最后一个空闲位。当使用完成时,将其放回链表。分配和释放都是O(1)的消耗。
- 链表设计时应注意使用指针指向 下一个空闲的内存块,而不是预先申请一个大的内存。
5.2.1.2 对齐分配
-
在大多数实现中,分配的额外字节数等于对齐。例如,如果请求的是一个16字节对齐的内存块,我们将分配额外的16个字节。这允许最坏情况下15个字节的地址调整,加上一个额外的字节,这样即使原始块已经对齐,我们也可以使用相同的计算。这样可以简化和加速代码,但每次分配都会浪费一个字节。它还很重要,因为我们将在下面看到,我们将需要这些额外的字节来存储将在块释放时使用的一些额外信息
-
我们通过屏蔽原始块内存地址的最不重要的位,从期望的对齐中减去这个位,并使用结果作为调整偏移量来确定必须调整的块地址的数量。对齐应该始终是两个字节(典型的是4字节和16字节对齐),因此要生成掩码,只需从对齐中减去一个。例如,如果请求的是一个16字节对齐的块,那么掩码将是(16-1)= 15= 0x0000000F。使用这个掩码的按位和和任何未对齐的地址将产生该地址未对齐的数量。例如,如果最初分配的块的地址是0x50341233,那么该地址与掩码0x0000000F共vields x00000000,因此该地址错对齐了三个字节。为了对齐地址,我们向它添加(对齐-不对齐)-(16-3)-13- oxd字节。因此最终对齐的地址是0x50341233 + 0xD= 0x50341240
对齐内存分配器实现示例:

-
当这个块稍后被释放时,代码将传递给我们调整后的地址,而不是我们分配的原始地址。那么,我们如何释放内存呢?我们需要一些方法将调整后的地址转换回原始的,可能是不对齐的地址。
-
为此,我们只需在分配的额外字节中存储一些元信息,以便首先对数据进行对齐。我们可能做的最小调整是一个字节。这样就有足够的空间来存储调整地址所使用的字节数(因为它永远不会超过字节数256)。我们总是将此信息存储在调整后的地址之前的字节中(无论我们实际添加了多少字节的调整),因此,给定调整后的地址,再次查找它是很容易的。这里的。修改后的allocateAligned()函数的外观。分配和释放对齐块的过程如Fiqure 5.3。

。
要求16字节对齐的对齐内存分配。分配的内存地址和调整的(对齐的)地址之间的差异存储在调整地址之前的字节中,以便在空闲时可以检索。
5.2.1.3 单帧和双缓冲内存分配器
-
实际上,所有的游戏引擎在游戏循环期间都至少分配一些临时数据。该数据在循环的每次迭代结束时丢弃2485. 引擎支持系统或用于下一帧,然后丢弃。这种分配模式非常常见,许多引擎都支持单帧和双缓冲的分配器。
-
单帧分配器: 通过保留一块内存并使用上面描述的简单堆栈分配器来管理它来实现的。在每一帧的开始,堆栈的“顶部”指针被清除到内存块的底部。随着帧数增长,不断往顶部分配。清洗和重复的方法。
-
单帧分配器的主要好处之一是,分配的内存不需要占用——我们可以依赖这样一个事实,即分配器将在每一帧开始时被清除。单帧分配器也非常快。最大的缺点是,使用单帧分配器需要程序员有合理的纪律。您需要认识到,从单帧缓冲区分配的内存块只在当前帧期间有效。程序员绝对不能跨帧边界缓存一个指向单帧内存块的指针!
-
双缓冲分配器:允许在 frame(i)上分配的内存块在frame(i+1)上使用。为此,我们创建了两个大小相同的单帧堆栈分配器,然后每帧都在它们之间来回移动.
-
这种分配器对于缓存多核游戏控制台异步处理的结果非常有用,比如Xbox 360、Xbox One PlayStation 3或PlayStation 4。在帧i上,我们可以在PS3的一个spu上启动异步作业,例如,将从双缓冲分配器分配的目标缓冲区的地址交给它。作业在第i帧结束之前运行并产生结果,并将它们存储到我们提供的缓冲区中。在帧(i+ 1),缓冲区被交换。作业的结果现在在非活动缓冲区中,因此它们不会被此帧期间可能进行的任何双缓冲分配覆盖。只要我们使用帧(i + 2)之前的作业结果,我们的数据就不会被覆盖
5.2.2 内存碎片化
-
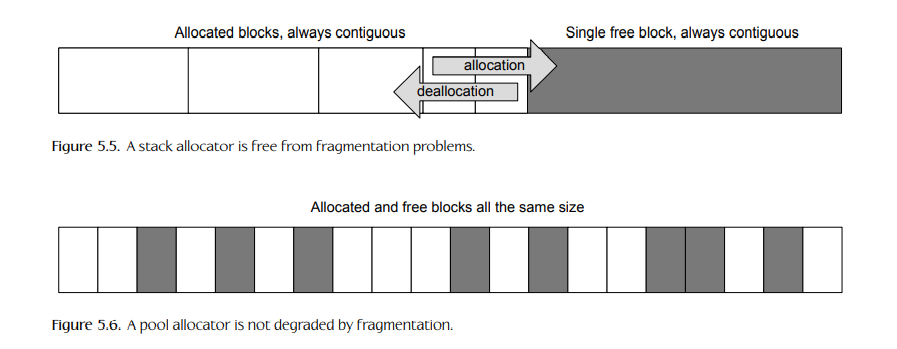
内存碎片的问题是,即使有足够的空闲字节来满足请求,分配也可能失败。问题的关键是分配的内存块必须始终是连续的。例如,为了满足一个128 KiB的请求,必须存在一个128 KiB或更大的空闲“洞”。如果有两个孔,每个孔的大小为64 KiB,那么就有足够的字节可用,但分配失败,因为它们不是连续的字节。
-
对于支持虚拟内存的操作系统来说,内存碎片并不是一个大问题。虚拟内存系统将称为页面的不连续的物理内存块映射到虚拟地址空间中,其中的页面在应用程序看来是连续的。当物理内存不足时,可以将陈旧的页面交换到硬盘,并在需要时从磁盘重新加载。有关虚拟内存如何工作的详细讨论,请参阅http://en.wikipedia.org/wiki/Virtual memory。大多数嵌入式系统无法实现虚拟内存系统。虽然一些现代的主机确实在技术上支持虚拟内存,但由于固有的性能开销,大多数主机游戏引擎仍然不使用虚拟内存。
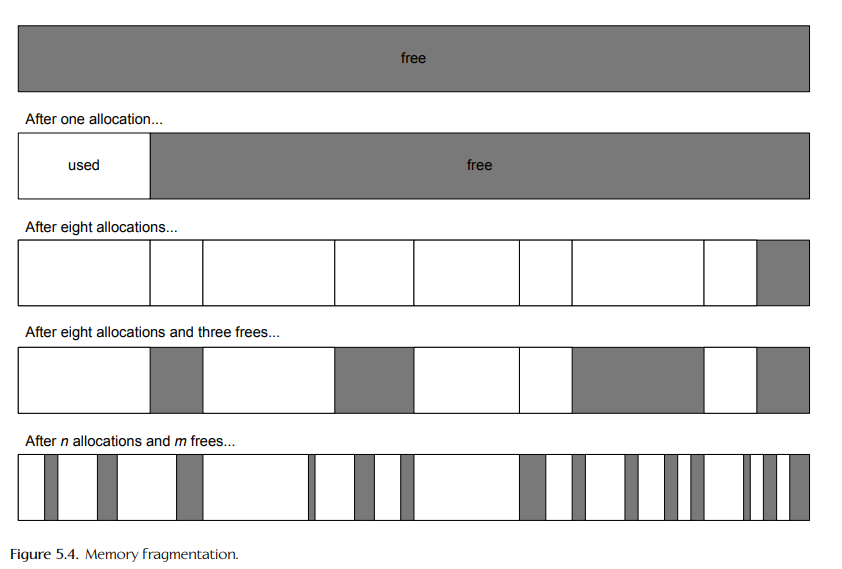
5.2.2.1 使用栈和池子分配器来避免内存碎片化
- 栈分配器不受碎片影响,因为分配总是连续的,块的释放顺序必须与它们被分配的顺序相反。如图所示。
- 池分配器也没有碎片问题。池会变成碎片化,但是碎片化不会像在一般用途的堆中那样造成内存不足的情况。池分配请求永远不会因为缺少足够大的连续空闲块而失败。因为所有的块大小都是一样的。如图所示。
5.2.2.2 碎片整理和重新安置
- 当以随机顺序分配和释放不同大小的对象时,既不能使用基于堆栈的分配器,也不能使用基于池的分配器。在这种情况下,可以通过定期整理堆碎片来避免碎片。碎片整理涉及到通过将分配的块从较高的内存地址移到较低的地址(从而将洞移到较高的地址)来合并堆中的所有空闲“洞”。一个简单的算法是搜索第一个“洞”,然后立即将分配的区块移到holc的开始位置。这样做的效果是“冒泡”到一个更高的内存地址的洞。如果重复这个过程,最终所有分配的块将占据堆地址空间低端的一个连续的内存区域,而所有的洞将在堆的高端冒泡成一个大洞。如图5.7所示。
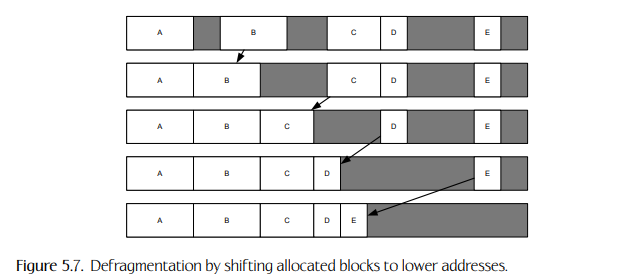
-
- 交换内存块并不是最大的问题,问题是: 移动一个分配的内存块,将会导致某个指向此内存块的指针失效。
- 2.上面描述的内存块的移动并不是特别需要技巧来实现的。需要注意的是,我们正在移动分配的内存块。如果任何人有一个指针指向这些已分配的块中的一个,那么移动该块将使该指针失效这个问题的解决方案是修补任何和所有的指针到一个移位的内存块,使他们指向正确的新地址后,移位。这个过程称为指针重定位。不幸的是,没有通用的方法来查找指向内存某个特定区域的所有指针。所以如果我们要支持内存碎片整理我们的游戏引擎,程序员必须仔细手动跟踪所有的指针,这样他们就可以被重新安置,或指针必须放弃支持更加适合搬迁的事情,如智能指针或句柄。
智能指针是一个包含指针的小类,它在大多数意图和目的中扮演指针的角色。但是因为智能指针是一个类,所以可以对它进行编码来正确地处理内存重定位。一种方法是安排所有智能指针将自己添加到一个全局链表中。每当在堆中移动一块内存时,就可以扫描所有智能指针的链表,并且可以适当地调整指向移位内存块的每个指针。
句柄通常实现为不可重定位表的索引,表本身包含指针。当一个已分配的块在内存中移位时,可以扫描句柄表,自动找到并更新所有相关的指针。因为句柄只是指针表的索引,所以无论内存块如何移动,它们的值都不会改变,所以使用句柄的对象不会受到内存重定位的影响。
-
当某些内存块无法重新定位时,就会出现重新定位的另一个问题。例如,如果您使用的第三方库可以做到这一点2545. 引擎支持系统不使用智能指针或句柄,任何指向其数据结构的指针都有可能是不可重定位的。解决这个问题的最佳方法通常是安排相关库从可重定位内存区域外的一个特殊缓冲区分配内存。另一种选择是简单地接受某些块是不可重定位的。如果不可重定位块的数量和大小都很小,那么重定位系统仍然可以运行得很好
-
均摊碎片整理成本碎片整理可能是一个缓慢的操作,因为它涉及到复制内存块。但是,我们不需要一次对堆进行完全的碎片整理。相反,代价可以平摊到多个帧上。我们可以允许在每一帧中移动N个已分配的块,比如8或16。如果我们的游戏每秒运行30帧,那么每帧持续1/30秒(33毫秒)。因此,堆通常可以在不到一秒的时间内被完全整理,而不会对游戏的帧率产生任何明显的影响。只要分配和分配的速度没有比碎片整理的速度快,堆就会一直保持大部分碎片整理。
-
这种方法仅在每个块的大小相对较小时有效,以便移动单个块所需的时间不超过分配给重新定位每个帧的时间。如果需要重新定位非常大的块,我们通常可以将它们分成两个或更多的子块,每个子块都可以独立地重新定位。这在Naughty Dog的引擎中并没有被证明是一个问题,因为重新定位只用于动态游戏对象,而且它们永远不会比几个kibibytes大——而且通常要小得多。
(5.3) 容器
- 常用的容器:
- 1.数组, 顺序存储结构,大小在编译时就固定了。
- 2.动态数组, 运行时长度动态变化
- 3.动态链表,顺序结构,但内存中存储地址不一定连续
- 4.栈,LIFO,后进先出
- 5.队列, FIFO, 先进先出
- 6.双向队列,支持高效的插入与删除操作
- 7.树,树型分组的结构,每个结点有0到1个父结点,和0到多个子结点。
- 8.二叉搜索树 BST: 每个结点只能最多有两个子结点,同时有一定顺序结构可按一定规则排序。 例如有红黑树,AVL 树,splay 树等
- 9.二叉堆,分为最大堆和最小堆。 必定满足完全二叉树,且有最大堆和最小堆的特性
- 10.优先队列, 一直保持一种排序好的状态的队列。通常由堆来实现(std::priority_queue), 很少用list来实现。
- 11.字典Dictionary, 键值对的存储容器, 也称为map, hash_table (std::map, std::hash_map)
- 12.集合Set,以一定规则存储一系列不重复的项。 类似于没有value的字典
- 13.图,集合里的结点互相连接,有向和无向。
- 14.有向无环图(DAG)。具有单向(即定向)互连的节点集合,没有循环(即不存在从同一节点开始和结束的非空路径)。
5.3.1 容器的操作
- 插入
- 删除
- 顺序读取:以一些“自然”预先定义好的顺序访问
- 随机存取:任意的顺序读取
- 查找
- 排序
5.3.2 迭代器
- 迭代器是一个小类,它“知道”如何有效地访问特定类型容器中的元素。它的作用类似于数组索引或指针——它一次引用容器中的一个元素,它可以被推进到下一个元素,并且它提供了某种机制来测试容器中的所有元素是否都被访问了。例如,下面两个代码片段中的第一个使用指针在c样式数组上迭代,而第二个使用几乎相同的语法在STL链表上迭代。
void processArray(int container[], int numElements) |
使用迭代器的好处
直接访问会破坏容器类的封装。另一方面,迭代器通常是容器类的朋友,因此它可以高效地迭代,而不向外界公开任何实现细节。(事实上,大多数好的容器类都隐藏其内部的实现,如果不用迭代器将无法遍历。)
迭代器可以简化迭代过程。大多数迭代器的作用类似于数组索引或指针,因此可以编写一个简单的循环,其中5. 引擎支持系统迭代器递增,并与终止条件进行比较,即使底层数据结构是任意复杂的。例如,迭代器可以使按顺序深度优先的树遍历看起来并不比简单的数组迭代复杂。
5.3.2.1 前增量与后增量
- 注意,在上面的示例中,我们使用的是c++的后增量运算符,而不是前增量运算符,++p。这是一个微妙但有时很重要的优化。在表达式中使用变量(现在已修改)的值之前,preincrement操作符递增变量的内容。后增量运算符在变量被使用后对其内容进行增量。这意味着编写++p会在代码中引入一个数据依赖项——CPU必须等待增量操作完成后,它的值才能在表达式中使用。在深度流水线化的CPU上,这将导致停机。另一方面,使用p++没有数据依赖性。变量的值可以立即使用,而递增操作可以稍后进行,也可以在使用它的同时进行。无论哪种方式,都不会在管道中出现失速。当然,在for循环的“update”表达式中(for(init_expr;test_expr;update_expr){…}),前后增量之间不应该有区别。这是因为任何好的编译器都能识别出update_expr中没有使用变量的值。但是在使用该值的情况下,后增量更优,因为它不会在CPU的管道中引入停顿。因此,养成使用后增量的aluays的习惯是很好的,除非您绝对需要前增量的语义。
5.3.3 算法复杂度
-
算法的顺序通常可以通过检查伪代码来确定。如果算法的执行时间完全不依赖于容器中元素的数量,我们就说它是O(1)(也就是说,它在常量时间内完成)。如果算法在容器中的元素上执行一个循环,并访问每个元素一次,比如在对未排序列表进行线性搜索时,我们称该算法为O(n)。如果两个循环是嵌套的,每个循环都可能访问每个节点一次,那么我们说算法是O(n2)。如果使用“分而治之”的方法,在一个二叉搜索(其中一半的列表是消除每一步),然后我们只能期望| log2 (n) + 1元素会被访问的算法在最坏的情况下,因此我们称它为O (logn)操作。如果一个算法执行一个子算法n次,且子算法为O(log n),则生成的算法将是O (nlogn)。
-
我们还应该考虑容器的内存布局和使用特性。例如,一个数组(例如int a[5]或std:: vector)在内存中连续存储它的元素,除了元素本身之外不需要额外的存储开销。(注意,动态数组确实需要一个小的固定开销。)另一方面,一个链表(例如,std:: list)包裹在“链接”的数据结构,每个元素也可能包含一个指针指向下一个元素和一个指向前一个元素,总共16字节的开销64位机器上的每个元素。此外,链表中的元素在内存中不需要是连续的,而且通常不是。一个连续的内存块通常比一组不同的内存块对缓存更友好。因此,对于高速算法,数组在缓存性能方面通常比链表更好(除非链表的节点本身就是从数组中分配的)2605. 引擎支持系统一个小的、连续的内存块)。但是链表更适合插入和删除元素的速度最重要的情况
5.3.4 创建自定义的容器类
- 许多游戏引擎都提供了它们自己的通用容器数据结构的自定义实现。这种做法在主机游戏引擎和针对移动电话和PDA平台的游戏中尤其普遍。自己构建这些类的原因包括:
- 总控制。您可以控制数据结构的内存需求、使用的算法、何时以及如何分配内存等。
- 优化的机会。您可以优化数据结构和算法,以利用特定于目标控制台的硬件特性;或者针对引擎中的特定应用程序对它们进行微调。
- 可定制性。您可以提供在第三方库(如STL)中不常见的自定义算法(例如,搜索容器中n个最相关的元素,而不是只搜索一个最相关的元素)。
- 消除外部依赖。由于软件是您自己构建的,所以您不需要任何其他公司或团队来维护它。如果出现问题,可以立即进行调试和修复,而不是等到库的下一个发行版(可能要等到你的游戏发行之后!)并发数据结构的控制。当您编写自己的容器类时,您可以完全控制在多线程或多核系统上保护它们不受并发访问的方法。例如,在PS4上,Naughty Dog为我们的大多数并发数据结构使用了轻量级的“旋转锁”互斥锁,因为它们在我们基于光纤的作业调度系统中工作得很好。第三方容器库可能无法提供这种灵活性
我们不能在这里涵盖所有可能的数据结构,但是让我们看看游戏引擎程序员处理容器的几种常见方法。
5.3.4.1 To Build or Not to Build
- 作为游戏引擎设计师,我们有以下几种选择:
-
- 手动构建所需的数据结构
-
- 依赖于第三方实现。一些常见的选择包括a. c++标准模板库(STL)b. STL的一种变体,如STLportc.强大而健壮的Boost库(http://www.boost.org)。STL和Boost都很有吸引力,因为它们提供了一组丰富而强大的容器类,涵盖了几乎所有可以想象到的数据结构类型。此外,这两个包都提供了一套功能强大的基于模板的通用算法——常见算法的实现,例如查找容器中的元素,这些算法可以应用于几乎任何类型的数据对象。然而,像这样的第三方软件包可能不适合somc类游戏cngincs。即使我们决定使用第三方包,我们也必须在Boost和各种风格的STL或其他第三方库之间进行选择。因此,让我们花一点时间来研究每种方法的优缺点。
STL:
Stl标准模板库的好处包括:
- STL提供了一组丰富的特性。
- 相当健壮的实现可以在各种各样的平台上使用。
- STL是几乎所有c++编译器的“标准”。
然而,STL也有很多缺点,包括:- STL有一个陡峭的学习曲线。文档现在已经很好了,但是头文件在大多数平台上都很晦涩,很难理解。
- STL通常比专门针对特定问题设计的数据结构要慢。
- STL几乎总是比定制设计的数据结构消耗更多的内存。
- STL需要进行大量的动态内存分配,有时要以适合高性能、内存有限的控制台游戏的方式控制它对内存的需求是一项挑战
- STL的实现和行为在不同的编译器之间略有不同,这使得它在多平台引擎中的使用更加困难。
因为现代pc上的高级虚拟内存系统使内存分配更便宜,而且耗尽物理RAM的可能性往往可以忽略不计。另一方面,STL通常不适合在内存有限、缺乏高级cpu和虚拟内存的控制台上使用。使用STL的代码可能不容易移植到其他平台。
以下是我使用的一些经验法则:
- 首先,也最重要的是,要了解您正在使用的特定STL类的性能和内存特征
- 尽量避免在您认为会成为性能瓶颈的代码中使用重的STL类。
- 在内存不是很重要的情况下,选择STL。举例来说,在游戏对象中嵌入std:: list是可以的,但是在3D网格的每个顶点中嵌入std:: list可能不是一个好主意。将3D网格的每个顶点添加到std::list可能也不行——std::list类会动态地为插入其中的每个元素分配一个小的“link”对象,这可能会导致大量微小的、碎片化的内存分配
- 如果您的引擎是多平台的,我强烈推荐STLport (http://www.stlport.org),这是一种STL实现,专门设计用于跨广泛的编译器和目标平台移植,比原始的STI mplementations更高效、功能更丰富。
Boost:
Boost项目是由c++标准委员会库工作组的成员发起的,但是现在它是一个开源项目,有许多来自世界各地的贡献者。该项目的目标是生成扩展STL并与之协同工作的库,用于商业和其他用途5.3。容器263非商业用途。许多Boost库已经包含在c++标准委员会的库技术报告(TR1)中,这是迈向成为未来c++标准的一部分的一步。
以下是Boost带来的好处的简要总结:
Boost提供了许多在STL中不可用的有用工具
在某些情况下,Boost提供了解决STL设计或实现中的某些问题的备选方案
Boost在处理一些非常复杂的问题(如智能指针)方面做得很好。(请记住,智能指针是复杂的东西,它们可能会影响性能。手柄通常更好;详见15.5节。)
Boost库的文档通常都很出色。文档不仅解释了每个库做什么以及如何使用它,而且在大多数情况下,它还对设计决策、约束和组合库的需求提供了极好的深入讨论。因此,阅读Boost文档是了解软件设计原理的好方法。
如果您已经在使用STL,那么Boost可以作为许多STL特性的优秀扩展和/或替代品。
不过,请注意下列注意事项:
大多数核心Boost类都是模板,因此使用它们所需要的只是一组适当的头文件。然而,一些Boost库构建到相当大的.lib文件中,可能不适合在非常小的游戏项目中使用。
虽然全球Boost社区是一个优秀的支持网络,但是Boost库并没有得到保证。如果您遇到一个bug,解决它或修复它最终将是您的团队的责任。
Boost库是在Boost软件许可下发布的。阅读许可信息(http://www.boost.org/more/license info)。小心地确保它适合您的引擎。
Loki
C++的模板元编程
到目前为止,最著名的、可能也是最强大的c++模板元编程库是Loki,它是由Andrei Alexandrescu设计和编写的(其主页在http://www.erdani.org)。该库可以从SourceForge获得,网址是Loki。Loki非常强大;这是一组令人着迷的代码,值得研究和学习。然而,它的两大弱点的实际性质:(a)的代码可以令人生畏的阅读和使用,更少的真正理解,(b)它的一些组件依赖于利用“side-effect” 的编译器Behaviours,需要小心仔细自定义以便在新的编译器上运行。因此,Loki使用起来有些困难,而且它的可移植性不如一些“不那么极端”的同类产品。洛基不适合胆小的人。也就是说,一些Loki的概念(如基于策略的编程)可以应用到任何c++项目中,即使您没有使用Loki library本身。我强烈推荐所有的软件工程师阅读Andrei开创性的书,现代c++设计[2],Loki库就是从这本书诞生的。
 wechat
wechat alipay
alipay